Na EmbedSocial, vejo o mesmo padrão repetidamente: as marcas estão cercadas por provas de clientes, mas seus sites ainda dependem de depoimentos desatualizados, capturas de ecrã manuais ou feeds de redes sociais antigos que não refletem mais o que os clientes estão dizendo hoje.
Por isso o debate web scraping vs API é tão importante no meu mundo.
No papel, ambos os métodos podem coletar dados online. Na prática, eles criam resultados muito diferentes quando seu objetivo é publicar resenhas atualizadas, UGC, e prova social em um site ao vivo.
Vi equipes começarem com um workaround rápido, apenas para descobrir que o desafio real não é coletar conteúdo gerado pelo utilizador uma vez.
O verdadeiro desafio é agregar e incorporar posts de redes sociais de forma confiável, moderá-los adequadamente e usá-los para se tornar mais confiável.
Bem, abaixo explico o que é web scraping, mostro como o web scraping funciona, detalho a diferença entre web scraping e API, e explico por que a agregação de redes sociais baseada em API como a EmbedSocial geralmente é o modelo melhor a longo prazo para marcas.
Antes de mergulhar, aqui está um resumo:
O que é web scraping?
Se alguém me perguntar o que é web scraping, minha resposta mais simples é esta:
É o processo de extrair informações visíveis de uma página da web e convertê-las em dados estruturados. Um scraper visita uma página, lê o que é exibido no HTML ou na interface renderizada, identifica os elementos que deseja e salva essas informações em um formato mais utilizável.
Definição de ‘Web scraping’
Essas informações podem incluir texto de resenha, nomes de utilizadores, legendas, classificações, detalhes de produtos, URLs de imagem, timestamps ou outros dados de acesso público.
É por isso que o scraping é popular em fluxos de trabalho pesados em pesquisa. As empresas podem extrair dados para casos de uso de escuta social, como rastreamento de concorrentes, análise de resenhas públicas, monitoramento de preços e, em alguns casos, web scraping de dados de redes sociais.
Quero ser justo aqui: scraping não é inerentemente errado ou inútil.
Pode ser prático quando nenhuma API adequada existe, ou quando o objetivo é análise interna em vez de publicação voltada para o cliente.
O problema começa quando as equipes assumem que um método construído para extração é automaticamente bom para operações contínuas de conteúdo do site.
Pela minha experiência, é aqui que as coisas começam a quebrar.
Como funciona o web scraping?
A maioria das explicações de como o web scraping funciona fica muito abstrata. Acho muito mais claro quando você a vê como um processo passo a passo:
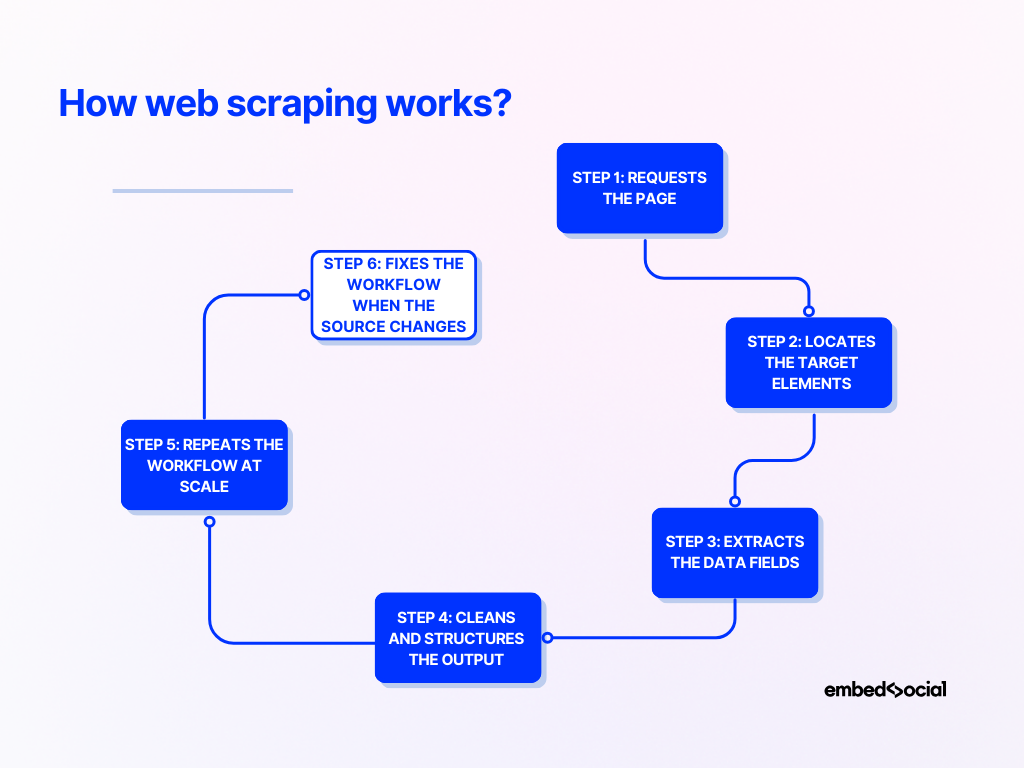
Passo 1: Solicita a página
Um scraper primeiro envia uma solicitação para o site de destino e recupera o conteúdo da página.
Em casos simples, isso significa baixar HTML bruto. Em casos mais difíceis, pode ser necessário renderizar JavaScript ou simular uma sessão do navegador.
Passo 2: Localiza os elementos de destino
Em seguida, o scraper varre a estrutura da página procurando pelos dados de que precisa.
Pode confiar em seletores CSS, nomes de classe, IDs de elemento, caminhos XPath, ou componentes repetidos para encontrar os blocos de conteúdo certos.
Passo 3: Extrai os campos de dados
Uma vez que os elementos de destino são localizados, o scraper puxa os campos úteis.
Isso pode incluir legendas, classificações, nomes de autores, hashtags, links de mídia, datas, texto de resenha, ou outros atributos visíveis.
Passo 4: Limpa e estrutura a saída
Os dados extraídos são frequentemente bagunçados.
Então o próximo passo é normalizar datas, remover caracteres extras, reformular campos e converter tudo em um formato estruturado como JSON ou CSV.
Passo 5: Repete o fluxo de trabalho em escala
Se o objetivo é coleta contínua, o scraper é executado repetidamente em várias páginas, perfis, feeds ou URLs de origem. É aqui que a carga de manutenção começa a aparecer.
Passo 6: Corrige o fluxo de trabalho quando a origem muda
Um scraper depende da estrutura da página. Se a plataforma de origem mudar como legendas, miniaturas ou elementos de página são carregados, o fluxo de trabalho pode falhar. Essa falha pode ser menor em um relatório interno, mas é muito mais séria quando o resultado aparece em um site público.
Neste caso, você tem que ajustar o scraper.
Exemplo da vida real:
Vi um feed de conteúdo social funcionar perfeitamente nos testes, depois degradar silenciosamente depois que uma plataforma mudou como os cartões de mídia foram renderizados. A equipe não apenas perdeu qualidade de dados. Eles acabaram com uma experiência de site quebrada.
O que é uma API?
Uma API, ou interface de programação de aplicações, é uma forma oficial para um sistema solicitar dados de outro em um formato estruturado.
Definição de ‘API’
Essa definição soa técnica, mas a diferença prática é simples.
Com scraping, você lê o que aparece na página. Com uma API, você solicita dados através de um canal construído para acesso de software.
Em vez de analisar conteúdo front-end visível, você recebe dados estruturados diretamente de endpoints definidos, frequentemente em JSON.
Isso geralmente torna o fluxo de trabalho mais fácil de manter.
Os dados são mais limpos, a estrutura é mais previsível, e a integração é menos dependente de como uma página se parece no navegador.
Claro, as APIs não são perfeitas. Elas podem ter limites, aprovações, quotas e regras controladas pelo provedor sobre quais dados estão disponíveis.
Mas para fluxos de trabalho recorrentes, especialmente aqueles vinculados a um site ao vivo, as APIs são geralmente uma base operacional muito mais forte.
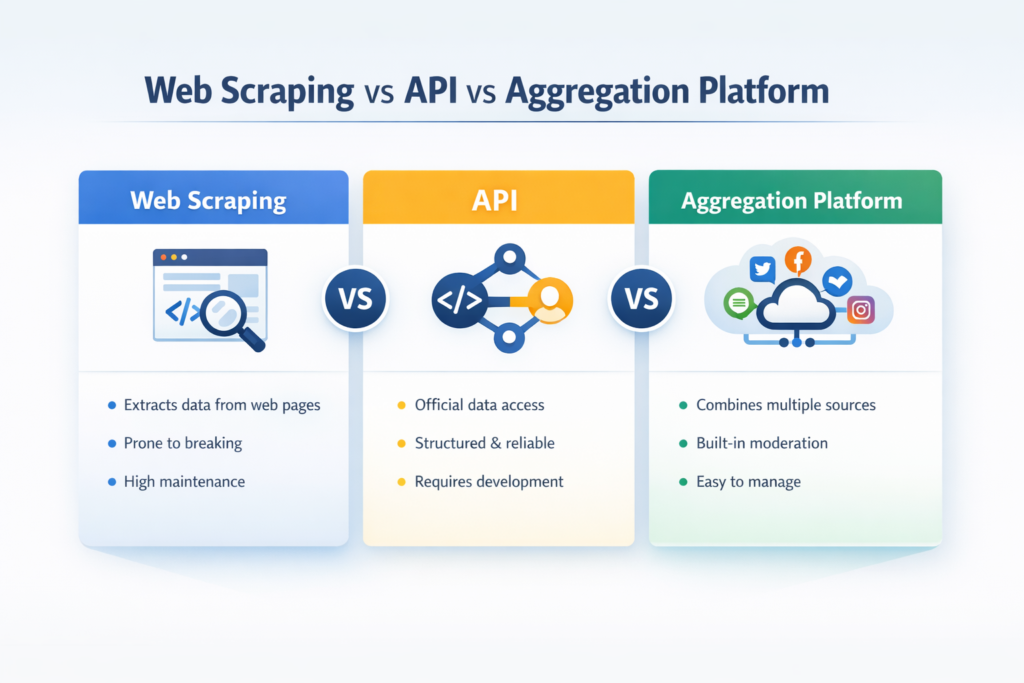
Web scraping vs API: as principais diferenças em um relance
Quando as pessoas procuram API vs web scraping ou web scraping vs API, geralmente querem uma comparação rápida e prática. Este é o framework que mais usualmente:
Web scraping
API
Fonte de dados
Conteúdo de página visível ou interface renderizada
Endpoint estruturado oficial
Formato de dados
Bruto ou semi-estruturado
Estruturado e mais fácil de integrar
Confiabilidade
Vulnerável a mudanças de layout e renderização
Geralmente mais estável
Manutenção
Mais alta
Mais baixa
Clareza de conformidade
Menos previsível
Geralmente mais clara
Flexibilidade
Alta para páginas públicas
Limitado ao que o provedor expõe
Melhor para
Pesquisa, monitoramento, extração única
Fluxos de trabalho de integração e publicação repetíveis
Adequação para prova social em sites
Frequentemente frágil
Geralmente muito melhor
A verdadeira diferença entre web scraping e API não é apenas de onde os dados vêm. É também quanto esforço vem após a coleta para manter o sistema utilizável, estável e pronto para publicação.
Prós e contras do web scraping
Como uma das palavras-chave principais de suporte aqui é prós e contras do web scraping, quero mostrar esse trade-off claramente em vez de simplificar demais.
Prós do web scraping
Contras do web scraping
Pode coletar dados públicos mesmo quando nenhuma API existe
Quebra quando layouts ou renderização mudam
Altamente flexível e customizável
Requer manutenção contínua
Útil para monitoramento, pesquisa e escuta social
Pode enfrentar sistemas anti-bot e bloqueios
Menos dependente da disponibilidade de API do provedor
A formatação de dados é frequentemente inconsistente
Útil para experimentos leves
Pode criar risco de política ou governança, dependendo do caso de uso
Pode capturar campos visíveis que as APIs podem não expor
Fit fraco para experiências de site polidas e voltadas para o cliente
Minha visão honesta é que o scraping é frequentemente mais forte quando a saída é interna. Uma vez que a saída se torna pública e sensível à marca, as fraquezas se tornam evidentes.
Vantagens de usar APIs
Se eu tivesse que resumir as principais vantagens de usar APIs para este caso de uso:
- Dados mais limpos e estruturados: por exemplo, quando uma marca puxa e incorpora avaliações do Google por meio de uma API, pode receber texto de resenha, classificações de estrelas, nomes de autores e timestamps em um formato previsível em vez de montá-los a partir de elementos de página bagunçados;
- Menos dependência de layouts front-end: por exemplo, se uma plataforma social reprojetar seus cartões de feed, uma conexão baseada em API pode continuar funcionando porque se baseia no endpoint de dados subjacente em vez da estrutura da página visível;
- Melhor ajuste para fluxos de trabalho repetíveis: por exemplo, uma empresa multi-localização pode coletar automaticamente avaliações recentes de dezenas de localidades em um único painel em vez de verificar manualmente cada página uma por uma;
- Melhor suporte para atualização e consistência: por exemplo, uma marca de e-commerce pode manter widgets de resenhas em páginas de produtos atualizados com feedback recente do cliente em vez de deixar os mesmos depoimentos estáticos no lugar por meses;
- Regras de governança e acesso mais claras: por exemplo, uma equipe de marketing usando integrações oficiais tem uma forma muito mais fácil de explicar de onde o conteúdo vem e como está sendo usado do que uma equipe confiando em páginas públicas raspadas;
- Menos limpeza e menos trabalhos de reparo depois: por exemplo, os desenvolvedores não precisam continuar corrigindo seletores quebrados toda vez que um site de origem muda sua estrutura HTML ou renderização de mídia;
- Um caminho mais fácil de coleta a publicação: por exemplo, uma marca pode mover prova social de fontes conectadas para um carrossel de página inicial ao vivo ou widget de resenha sem juntar ferramentas de web scraping não confiáveis.
Em resumo, as APIs não apenas ajudam você a coletar dados. Elas ajudam você a construir um sistema em torno desses dados. A extração de dados se torna um processo confiável que fornece acesso a dados estruturados.
Além disso, as APIs permitem que você segmente páginas do site para obter dados específicos em vez de raspar tudo de ditas páginas e depois peneirar os conteúdos.
Por que os dados de redes sociais são diferentes dos dados gerais da web?
A maioria dos artigos genéricos sobre web scraping vs API trata todos os dados online como se pertencessem ao mesmo balde. Pela minha experiência, é aqui que a análise fica muito superficial.
O conteúdo de redes sociais deixa de ser apenas ‘dados’ no momento em que aparece em uma página inicial, página de produto ou widget de resenha. Nesse ponto, ele se torna conteúdo que constrói confiança.
Caso de uso de dados gerais da web
Caso de uso de dados de redes sociais
Frequentemente usado para análise interna
Frequentemente usado para prova voltada para o cliente
Problemas de formatação menores podem ser aceitáveis
A formatação afeta diretamente a percepção
Uma lacuna temporária pode ser inconveniente
Um feed quebrado pode danificar a confiança
Geralmente focado em recuperação
Requer recuperação, moderação e publicação
Muitas vezes vive em painéis ou relatórios
Vive em sites, widgets e páginas de conversão
Risco de marca menor se apenas interno
Risco de marca mais alto porque os clientes o veem
É por isso que separo tão fortemente esses casos de uso. Uma planilha pode tolerar saída bagunçada. Um widget UGC ao vivo não pode. Você não apenas extrai dados de páginas da web, você reimplementa esses dados em widgets de confiança de construção, widgets de site ao vivo que atualizam automaticamente.
Web scraping de dados de redes sociais: onde quebra?
O apelo do web scraping de dados de redes sociais é óbvio no início. O conteúdo público parece acessível, a configuração pode parecer rápida e as equipes podem acreditar que encontraram um atalho.
Na prática, o modelo começa a quebrar de maneiras previsíveis:
Mudanças front-end criam fragilidade
As plataformas sociais mudam frequentemente.
Um feed que depende da estrutura da página visível pode parar de funcionar quando uma legenda carrega diferentemente, um elemento de mídia é reestruturado ou a plataforma muda como a interface é renderizada.
Dica profissional:
Nunca construa um feed voltado para o cliente apenas em suposições de layout de página. Se uma plataforma mudar como legendas, cartões ou mídia são renderizados, seu feed pode quebrar da noite para o dia. É por isso que o acesso à API oficial é geralmente a base mais segura para qualquer coisa pública.
A qualidade de formatação fica difícil de controlar
Mesmo quando um scraper funciona tecnicamente, a saída pode não estar pronta para publicação.
Vi conteúdo social raspado vir com legendas faltando, renderização de mídia pobre, layouts de cartão desiguais e atribuição incompleta.
Dica profissional:
Um feed que ‘funciona tecnicamente’ não é a mesma coisa que um feed pronto para publicação. Antes que o conteúdo fique ao vivo, certifique-se de que você pode controlar de forma confiável legendas, qualidade de mídia, atribuição, consistência de cartão e comportamento de fallback em todos os layouts.
A moderação se torna um ônus manual
Uma vez que o conteúdo é coletado, alguém ainda precisa decidir o que realmente deve ficar ao vivo.
Isso significa gestão de UGC como filtrar spam, remover posts irrelevantes, excluir conteúdo de baixa qualidade e verificar se o resultado final ainda se sente na marca.
Dica profissional:
A coleta de conteúdo é apenas metade do trabalho. A verdadeira vitória operacional vem de ter fluxos de trabalho de gestão de UGC integrados para filtrar spam, remover posts irrelevantes, destacar o melhor conteúdo e manter cada widget alinhado com seus padrões de marca.
A escala multiplica o custo de manutenção
Um feed experimental é gerenciável.
Vários feeds em páginas de produtos, campanhas e sites de clientes criam um ônus de manutenção muito diferente. A coleta de dados em larga escala precisa de acesso à API. Se você deseja obter dados, dados confiáveis em escala, você precisa de acesso direto à disponibilidade de dados.
Dica profissional:
Um feed experimental pode ser gerenciável com scraping, mas a coleta de dados em larga escala é um jogo diferente. Uma vez que você precisa de conteúdo confiável em várias páginas, campanhas ou sites de clientes, o acesso direto à disponibilidade de dados estável importa muito mais do que a velocidade de configuração de curto prazo.
A governança fica mais difícil de gerenciar
Dependendo da plataforma, tipo de conteúdo e caso de uso, o scraping pode gerar perguntas extras em torno de termos, privacidade, acesso e risco de marca.
Para muitas equipes, essa incerteza sozinha torna uma base fraca para prova voltada para o cliente.
Dica profissional:
Se o conteúdo influenciará decisões de confiança ou compra, o método de coleta deve ser julgado por confiabilidade e governança, não apenas por se conseguir puxar os dados uma vez.
API direta vs API de agregação: qual é a diferença?
Esta é a distinção que a maioria dos artigos API vs web scraping perdem. Muitas equipes pensam que a escolha é simplesmente entre scraping e usar uma API.
Na realidade, a comparação mais útil é entre scraping, integração direta de API e uma camada gerenciada de agregador de redes sociais.
O que você ganha
Principal desvantagem
Melhor para
Web scraping
Acesso flexível a conteúdo público visível
Frágil, pesado em manutenção, confuso para publicação
Pesquisa, monitoramento, experimentos
Integração de API direta
Acesso estruturado oficial aos dados de origem
Você ainda precisa construir moderação, sincronização, formatação e lógica de publicação
Equipes técnicas com recursos de desenvolvimento
API de agregação ou plataforma
Acesso oficial mais fluxo de trabalho, moderação, organização e ferramentas de publicação
Menos controle bruto do que sistemas totalmente personalizados
Marcas, profissionais de marketing, agências, equipes de e-commerce
O acesso direto à API é poderoso. Mas muitas equipes subestimam o que vem depois da conectividade. Uma vez que você tem os dados, você ainda precisa gestão de origem, regras de moderação, lógica de transformação, ciclos de atualização, geração de widget e manutenção contínua.
É por isso que continuarei voltando ao mesmo ponto: acesso bruto não é a mesma coisa que um pipeline de prova social funcionando. Você precisa de um agregador de redes sociais como EmbedSocial.
Quando web scraping ainda faz sentido?
Não acho que um artigo credível sobre web scraping vs API deva fingir que o scraping não tem lugar. Absolutamente tem. Um bom exemplo é escuta social.
Se uma equipe quer monitorar conversas públicas, explorar discussões visíveis ou coletar dados para análise interna, o scraping pode ser prático e eficiente.
Outro exemplo é coleta de dados de nicho público.
Às vezes, a informação necessária é pública, mas nenhuma API útil existe. Nesses casos, o scraping pode ser o único caminho realista para os dados.
Também acho que o scraping pode fazer sentido para experimentos internos leves.
Se o fluxo de trabalho é temporário, a equipe entende a fragilidade e nada voltado para o cliente depende dele, o trade-off pode ser aceitável.
Mas uma vez que o conteúdo se torna parte da experiência da marca pública, geralmente aconselho as equipes a elevar o padrão. É aqui que o scraping frequentemente começa a se tornar um passivo.
Por que a agregação de redes sociais baseada em API é o sistema melhor a longo prazo para marcas?
É aqui que o caso de negócios fica muito mais claro. Um modelo de agregação baseado em API é melhor para marcas porque resolve mais do que coleta.
Ajuda a gerenciar o ciclo de vida completo do conteúdo após a coleta.
Pegue uma marca de e-commerce em crescimento como exemplo.
Pode querer resenhas recentes em páginas de produtos, UGC em páginas de desembarque e prova social na página inicial. Tentar manter isso através de soluções alternativas espalhadas cria arrasto muito rapidamente. A agregação centralizada baseada em API torna esse sistema gerenciável.
Um negócio de serviços é outro bom exemplo.
Substituir capturas de ecrã estáticas de depoimentos por conteúdo de resenha ao vivo pode fazer o site parecer mais atual, mais acreditável e mais alinhado com o que os clientes estão dizendo agora. Imagine uma página wall-of-love em seu site que atualiza automaticamente.
Também me importo com quanto trabalho um sistema cria nos bastidores. Um bom fluxo de trabalho reduz capturas de ecrã, curação manual, tíquetes de desenvolvedor repetitivos e correções de emergência.
Exemplo do meu trabalho na EmbedSocial:
Vi empresas substituir um bloco de depoimento desatualizado com um fluxo ao vivo de resenhas recentes do Google e menções sociais. O resultado não era apenas conteúdo mais fresco. O site se sentia mais ativo, mais atual e mais credível.
Como EmbedSocial transforma prova social em um ativo de site vivo?
Esta é a parte que conheço mais diretamente da experiência prática.
Na EmbedSocial, o objetivo não é apenas ajudar marcas a coletar conteúdo. É ajudá-las a transformar conteúdo real de clientes em algo organizado, moderado e pronto para publicação.
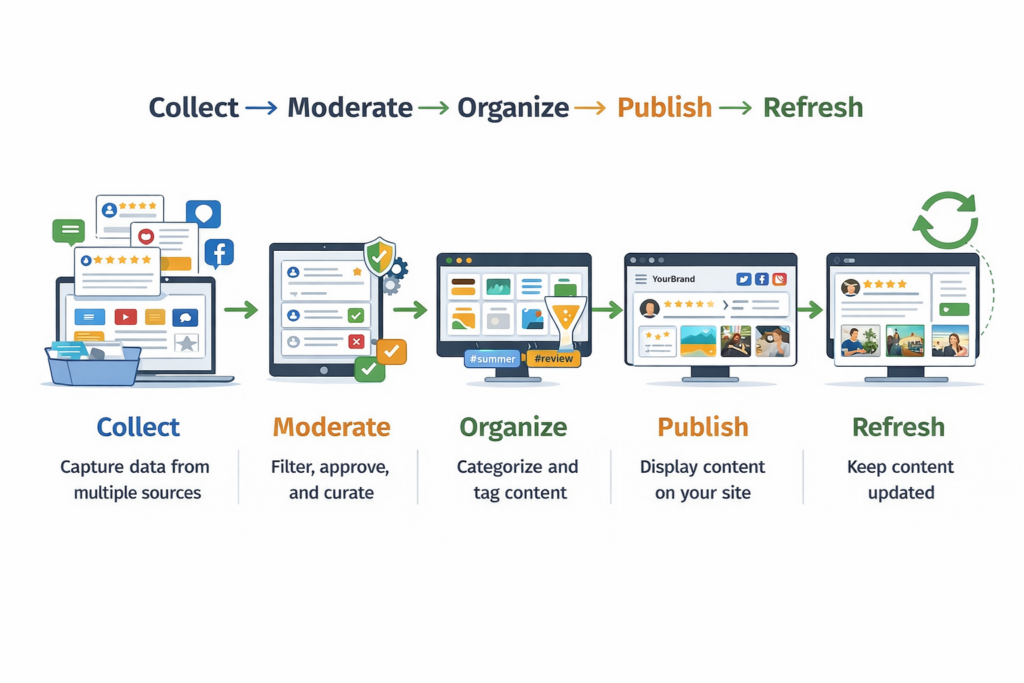
Aqui está um gráfico simples cobrindo o processo de agregação de conteúdo de redes sociais:
E aqui estão os passos que você precisa completar após criar sua conta EmbedSocial:
Passo 1: Envie um prompt de design de widget de IA
Primeiro, você tem que solicitar ao editor de widget de IA que crie seu novo widget de redes sociais:
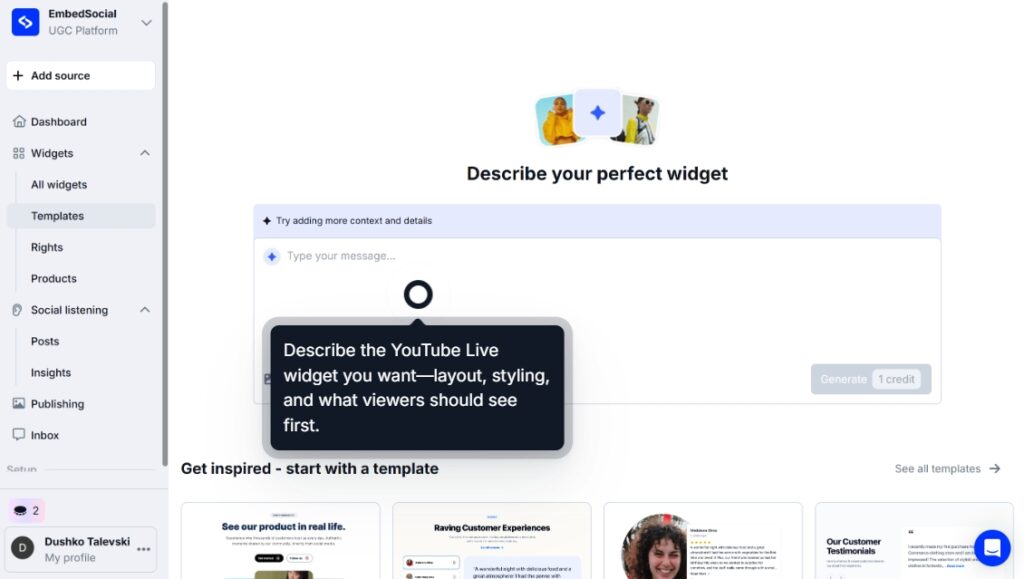
Passo 2: Conecte suas fontes de redes sociais
Então, você tem que conectar suas redes sociais para puxar seu conteúdo na EmbedSocial:
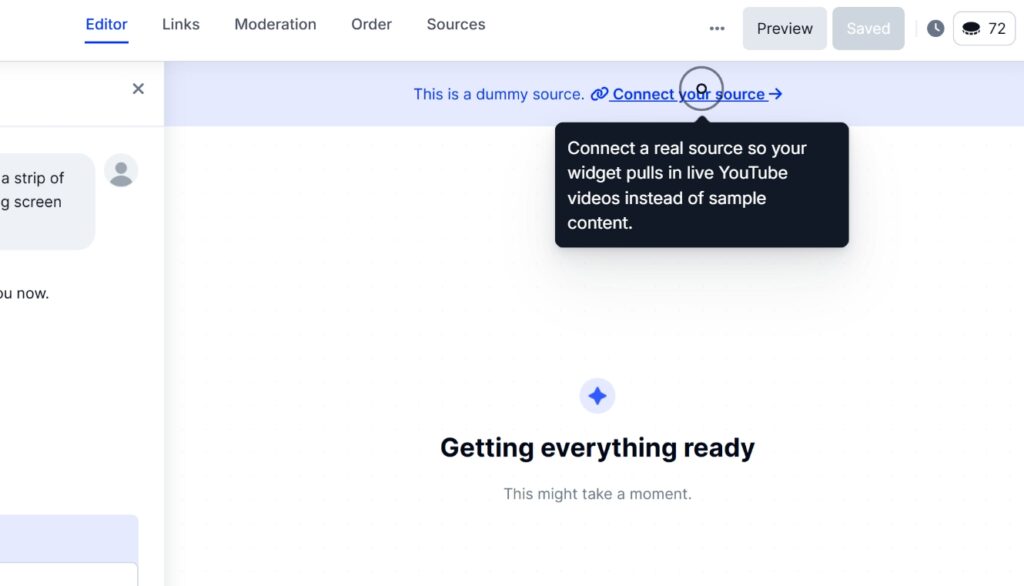
Passo 3: Projete e customize seu widget
Então, você pode selecionar o modelo do seu widget e personalizá-lo ainda mais através de prompts de IA:
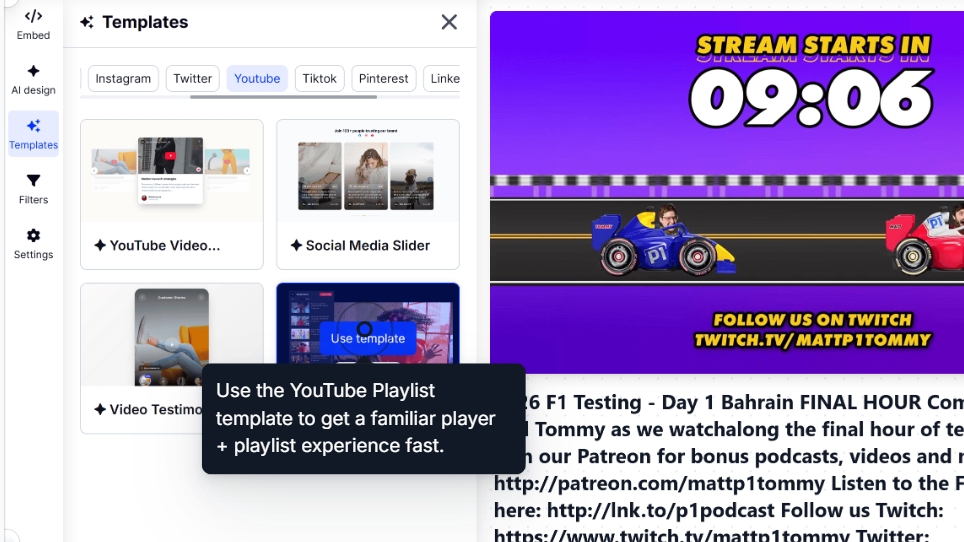
Se você não estiver satisfeito com a aparência do widget, basta navegar até o design de IA e adicionar mais prompts:
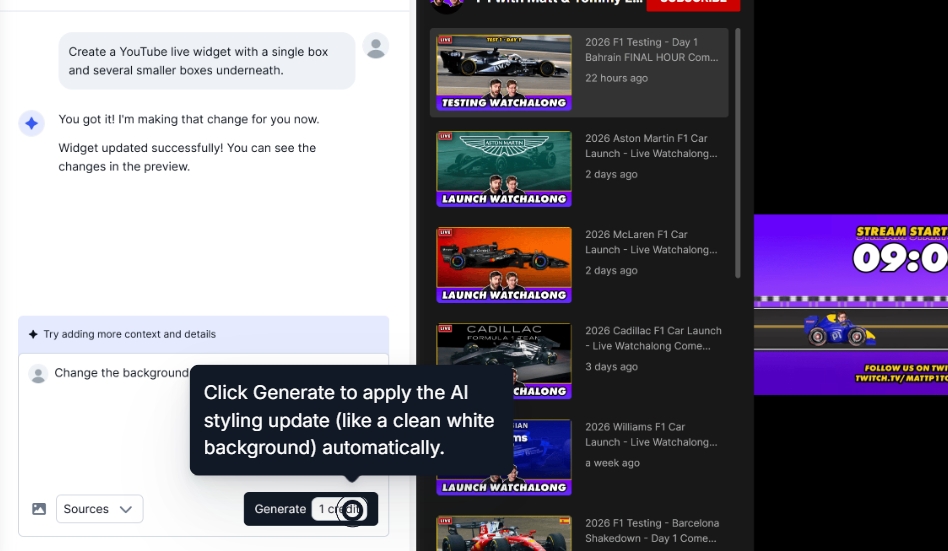
Passo 4: Modere o conteúdo do seu widget
Dirija-se à aba Moderação para selecionar posts específicos que você deseja apresentar:
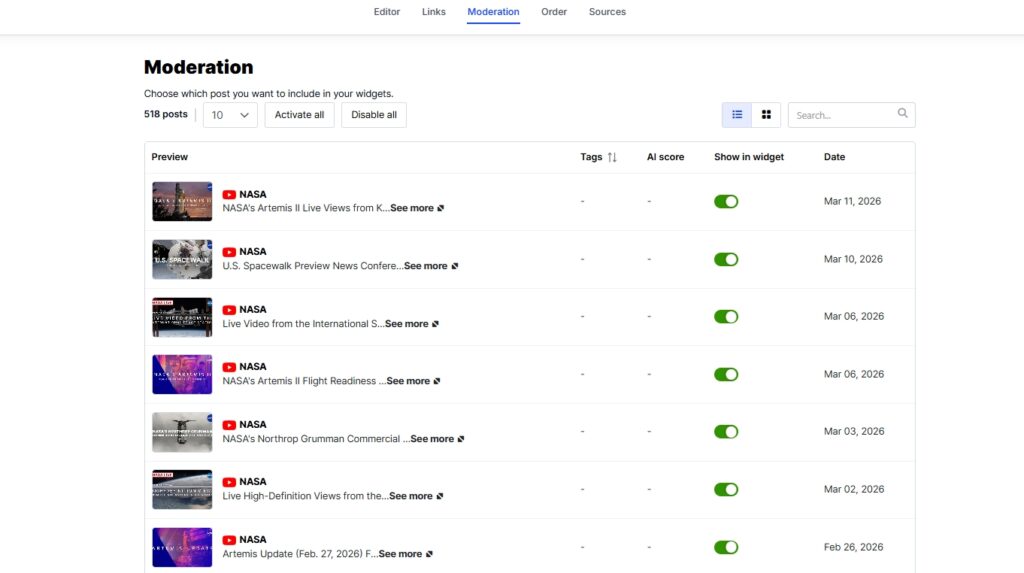
Passo 5: Publique os widgets no site
Depois que o widget ou feed estiver pronto, você precisa copiar seu código incorporável através da aba Incorporar:
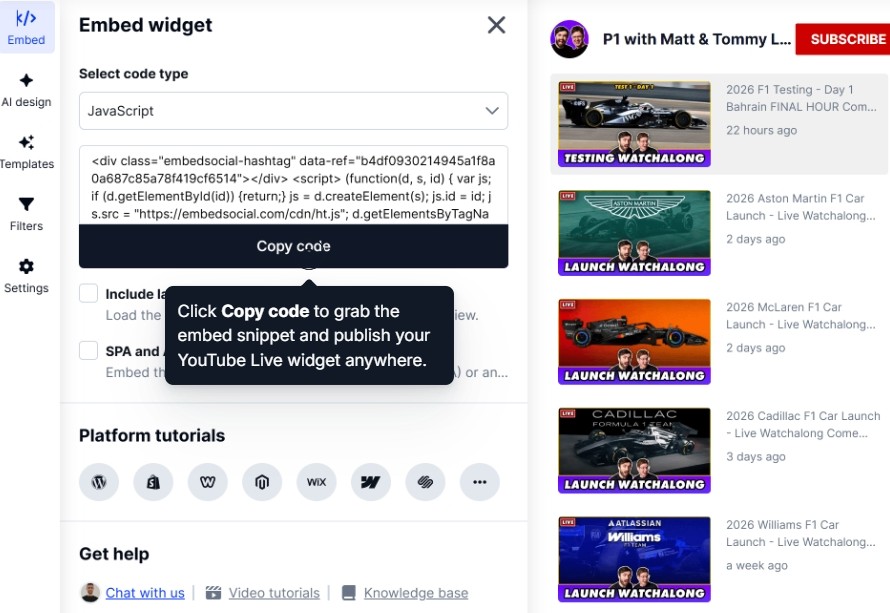
Passo 6: Cole o código do widget no seu site
A última coisa que você precisa fazer é navegar até seu construtor de site e colar o código do widget.
Aqui está como funciona em todos os construtores de site populares:
Conclusão: use plataformas de UGC com acesso à API para construir um fluxo de trabalho confiável de prova social!
A razão pela qual web scraping vs API permanece uma pergunta tão comum é simples: ambos os métodos podem ajudar a coletar dados online. Mas para marcas, esse enquadramento ainda é muito estreito.
A pergunta melhor é como transformar conteúdo de redes sociais em uma experiência estável, confiável e voltada para o cliente que mantém o site atualizado ao longo do tempo.
Da minha perspectiva, o scraping ainda tem um lugar em pesquisa, monitoramento e análise exploratória. Mas quando o objetivo é publicar prova social em um site ao vivo, um fluxo de trabalho de agregação baseado em API é geralmente a resposta mais inteligente a longo prazo.
Essa abordagem oferece a você mais do que acesso.
Oferece a você estrutura, moderação, consistência e um caminho realista de conteúdo de cliente espalhado para widgets de site ao vivo que realmente constroem confiança.
FAQs sobre web scraping vs API para conteúdo de redes sociais
Qual é a diferença entre usar uma API e web scraping?
A principal diferença entre web scraping e API é como os dados são acessados.
Web scraping puxa informações do que aparece em uma página da web, enquanto uma API fornece dados estruturados através de um ponto de acesso oficial projetado para integração de software.
Usar uma API é melhor do que web scraping?
Quando as equipes comparam API vs web scraping, a resposta depende do caso de uso.
Para pesquisa ou monitoramento único, o scraping pode fazer sentido. Para fluxos de trabalho repetíveis e conteúdo de site voltado para o cliente, as APIs são geralmente a escolha mais forte.
O que é web scraping em termos simples?
Se eu tivesse que responder o que é web scraping em uma frase, eu diria que é o processo de coletar automaticamente informações visíveis de páginas da web e convertê-las em dados estruturados.
É por isso que é frequentemente usado em monitoramento, coleta de dados públicos e fluxos de trabalho de pesquisa.
Como funciona o web scraping passo a passo?
Em um nível básico, como o web scraping funciona segue uma sequência.
Um scraper solicita uma página, lê o HTML ou conteúdo renderizado, identifica os elementos de destino, extrai os campos necessários e os salva em um formato estruturado como JSON ou CSV.
Quais são os prós e contras do web scraping?
Os principais prós e contras do web scraping se resumem a flexibilidade versus confiabilidade.
O scraping é flexível porque pode coletar dados públicos mesmo quando nenhuma API existe, mas também é mais frágil, mais pesado em manutenção e geralmente um ajuste mais fraco para experiências de site voltadas para o cliente.
Quais são as principais vantagens de usar APIs?
As principais vantagens de usar APIs são estrutura, consistência e repetibilidade.
As APIs geralmente retornam dados mais limpos, são menos dependentes de mudanças de página front-end e são mais fáceis de conectar a fluxos de trabalho de longo prazo.
Você pode usar web scraping para dados de redes sociais?
Sim, web scraping de dados de redes sociais é possível em algumas situações.
Mas pela minha experiência, é muito menos confiável quando o objetivo é publicar esse conteúdo em um site ao vivo onde formatação, atualização e moderação importam.
Por que feeds scrapeados quebram tão frequentemente?
Feeds scrapeados frequentemente quebram porque dependem da estrutura da página.
Se uma plataforma mudar como legendas, miniaturas, cartões de mídia ou outros elementos são renderizados, o scraper pode parar de retornar dados completos ou consistentes.
Quando web scraping ainda faz sentido?
Web scraping ainda faz sentido para pesquisa, escuta social, coleta de dados públicos e alguns experimentos internos.
Fico muito mais cauteloso ao recomendá-lo quando o conteúdo é destinado a uma experiência de marca voltada para o cliente.
Qual é a diferença entre uma API direta e uma plataforma de agregação?
Uma API direta fornece acesso bruto aos dados de origem.
Uma plataforma de agregação pega esse acesso e o transforma em um fluxo de trabalho utilizável ajudando você a coletar, moderar, organizar e publicar conteúdo em várias fontes.
Posso exibir conteúdo de redes sociais no meu site sem scraping?
Sim.
Na verdade, para a maioria das marcas, esse é o caminho melhor. Um fluxo de trabalho de agregação baseado em API permite que você colete prova social através de conexões oficiais e a publique através de widgets, carrosséis, galerias ou feeds de resenha sem depender de métodos de scraping frágeis.
O web scraping é mais barato do que APIs?
Nem sempre.
O scraping pode parecer mais barato no início, mas o ônus de manutenção de longo prazo frequentemente muda o cenário de custos uma vez que correções, monitoramento, problemas de formatação e quebra pública enfrentada são adicionados.
A agregação de redes sociais baseada em API é melhor para marcas?
Para a maioria das marcas, sim.
Quando o objetivo é manter um site atualizado com conteúdo confiável de clientes, agregação baseada em API é geralmente o sistema melhor a longo prazo porque suporta coleta, moderação e publicação em um único fluxo de trabalho.
![11 Melhores Widgets de Redes Sociais para Sites [+Principais Casos de Uso]](https://embedsocial.com/wp-content/uploads/2023/11/embedsocial-ugc-software-landing-page-1024x688.jpg)
![Como incorporar testemunhos num site em 2026 [2 métodos + dicas]](https://embedsocial.com/wp-content/uploads/2024/09/embed-trustpilot-reviews-step-01-use-ai-to-describe-your-widget-1024x576.webp)
![Como Incorporar Galeria de Vídeos em Sites [+ 5 Modelos de Widget]](https://embedsocial.com/wp-content/uploads/2026/02/youtube-channel-section.jpg)