Bei EmbedSocial sehe ich immer wieder das gleiche Muster: Marken sind von Kundenbeweisen umgeben, aber ihre Websites verlassen sich dennoch auf veraltete Testimonials, manuelle Screenshots oder veraltete Social-Media-Feeds, die nicht mehr widerspiegeln, was Kunden heute sagen.
Deshalb ist die Debatte zwischen Web Scraping und API in meiner Welt so wichtig.
Theoretisch können beide Methoden Online-Daten sammeln. In der Praxis führen sie zu sehr unterschiedlichen Ergebnissen, wenn das Ziel darin besteht, aktuelle Bewertungen, UGC und Social Proof auf einer Live-Website zu veröffentlichen.
Ich habe Teams erlebt, die mit einem schnellen Workaround angefangen haben, nur um festzustellen, dass die eigentliche Herausforderung nicht darin besteht, Inhalte von Benutzern einmal zu sammeln.
Die echte Herausforderung besteht darin, Social-Media-Beiträge zuverlässig zu aggregieren und einzubetten, sie richtig zu moderieren und damit vertrauenswürdiger zu werden.
Nun erkläre ich unten, was Web Scraping ist, zeige, wie Web Scraping funktioniert, schlüssele den Unterschied zwischen Web Scraping und API auf und erkläre, warum API-basierte Social Aggregation wie EmbedSocial, normalerweise das bessere Langzeit-Modell für Marken ist.
Bevor ich anfange, hier ist die Zusammenfassung:
Was ist Web Scraping?
Wenn mich jemand fragt, was Web Scraping ist, ist meine einfachste Antwort diese:
Web Scraping ist der Prozess, bei dem sichtbare Informationen von einer Webseite extrahiert werden und in strukturierte Daten umgewandelt werden. Ein Scraper besucht eine Seite, liest das, was im HTML oder in der gerenderten Schnittstelle angezeigt wird, identifiziert die gewünschten Elemente und speichert diese Informationen in einem besser nutzbaren Format.
Definition von “Web Scraping”
Diese Informationen können Bewertungstexte, Benutzernamen, Beschriftungen, Ratings, Produktdetails, Bild-URLs, Zeitstempel oder andere öffentlich zugängliche Daten enthalten.
Deshalb ist Scraping in forschungsintensiven Workflows beliebt. Unternehmen können Daten für Social Listening Anwendungen extrahieren, wie zum Beispiel Wettbewerbsverfolgung, öffentliche Bewertungsanalyse, Preisüberwachung und in einigen Fällen Web Scraping von Social-Media-Daten.
Ich möchte hier fair sein: Scraping ist nicht inhärent falsch oder nutzlos.
Es kann praktisch sein, wenn keine geeignete API existiert, oder wenn das Ziel die interne Analyse statt kundenorientierte Veröffentlichung ist.
Das Problem beginnt, wenn Teams davon ausgehen, dass eine für die Extraktion gebaute Methode automatisch gut für laufende Website-Inhaltsoperationen ist.
Nach meiner Erfahrung ist hier der Punkt, an dem die Dinge zu brechen anfangen.
Wie funktioniert Web Scraping?
Die meisten Erklärungen, wie Web Scraping funktioniert, bleiben zu abstrakt. Ich denke, es wird viel klarer, wenn man es als schrittweisen Prozess betrachtet:
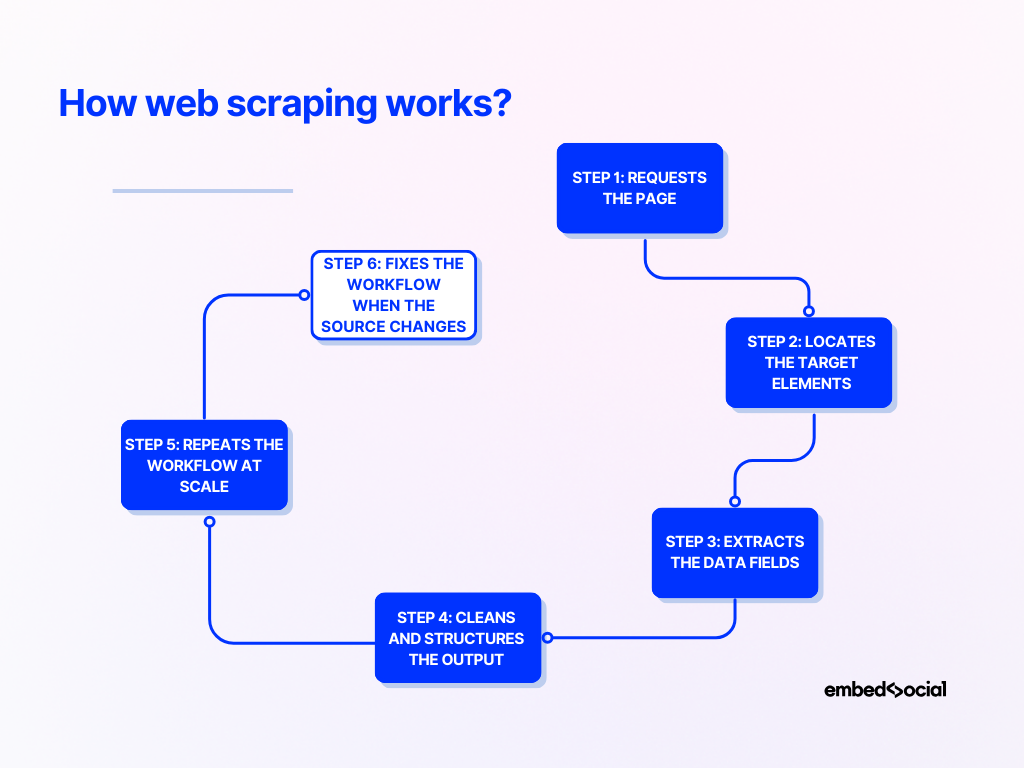
Schritt 1: Fordert die Seite an
Ein Scraper sendet zunächst eine Anfrage an die Zielwebsite und ruft den Seiteninhalt ab.
In einfachen Fällen bedeutet das Download von rohem HTML. In schwierigeren Fällen kann es sein, dass JavaScript gerendert oder eine Browser-Sitzung simuliert werden muss.
Schritt 2: Sucht die Zielelemente
Der Scraper scannt dann die Seitenstruktur nach den benötigten Daten.
Er könnte sich auf CSS-Selektoren, Klassennamen, Element-IDs, XPath-Pfade oder wiederholte Komponenten verlassen, um die richtigen Inhaltsblöcke zu finden.
Schritt 3: Extrahiert die Datenfelder
Sobald die Zielelemente gefunden sind, extrahiert der Scraper die nützlichen Felder.
Dies kann Bildunterschriften, Ratings, Autorennamen, Hashtags, Medien-Links, Daten, Bewertungstexte oder andere sichtbare Attribute enthalten.
Schritt 4: Bereinigt und strukturiert die Ausgabe
Gescrapte Daten sind oft ungeordnet.
Der nächste Schritt besteht also darin, Daten zu normalisieren, zusätzliche Zeichen zu entfernen, Felder umzustrukturieren und alles in ein strukturiertes Format wie JSON oder CSV umzuwandeln.
Schritt 5: Wiederholt den Workflow im großen Maßstab
Wenn das Ziel eine laufende Sammlung ist, läuft der Scraper wiederholt über mehrere Seiten, Profile, Feeds oder Quellen-URLs. Hier beginnt sich die Wartungslast zu zeigen.
Schritt 6: Behebt den Workflow, wenn sich die Quelle ändert
Ein Scraper hängt von der Seitenstruktur ab. Wenn die Quellplattform ändert, wie Bildunterschriften, Thumbnails oder Seitenelemente geladen werden, kann der Workflow fehlschlagen. Dieser Fehler kann in einem internen Bericht gering sein, ist aber viel ernster, wenn das Ergebnis auf einer öffentlichen Website angezeigt wird.
In solch einem Fall muss man den Scraper anpassen.
Beispiel aus der Praxis:
Ich habe einen Social-Content-Feed gesehen, der beim Testen perfekt funktionierte, dann aber leise abbröckelte, nachdem eine Plattform änderte, wie Media-Karten gerendert wurden. Das Team verlor nicht nur Datenqualität. Sie endeten mit einem defekten Website-Erlebnis.
Was ist eine API?
Eine API oder Application Programming Interface ist eine offizielle Möglichkeit für ein System, Daten von einem anderen in einem strukturierten Format anzufordern.
Definition von “API”
Diese Definition klingt technisch, aber der praktische Unterschied ist einfach.
Beim Scraping liest man, was auf der Seite angezeigt wird. Bei einer API fordern Sie Daten über einen für Software-Zugriff gebauten Kanal an.
Statt sichtbare Frontend-Inhalte zu analysieren, erhält man strukturierte Daten direkt von definierten Endpunkten, oft in JSON.
Das macht den Workflow normalerweise einfacher zu pflegen.
Die Daten sind sauberer, die Struktur ist vorhersehbarer, und die Integration hängt weniger davon ab, wie eine Seite im Browser aussieht.
Natürlich sind APIs nicht perfekt. Sie können Limits, Genehmigungen, Quoten und von Providern kontrollierte Regeln über verfügbare Daten haben.
Aber für wiederkehrende Workflows, besonders solche, die an eine Live-Website gebunden sind, sind APIs normalerweise eine viel stärkere operative Grundlage.
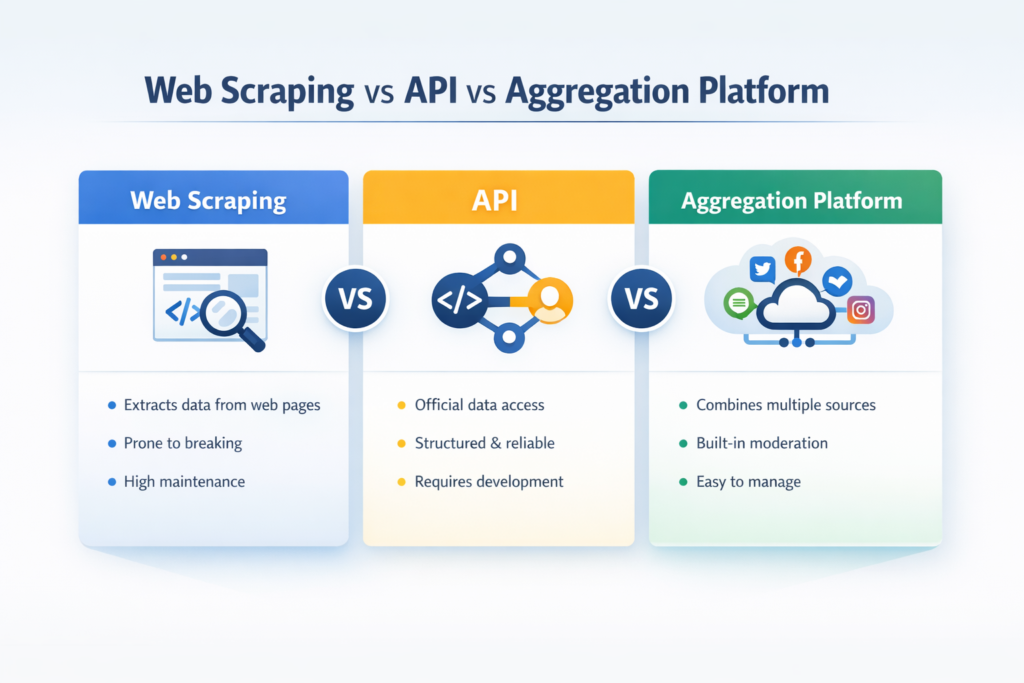
Web Scraping vs. API: die wichtigsten Unterschiede auf einen Blick
Wenn Menschen API vs. Web Scraping oder Web Scraping vs. API suchen, wollen sie normalerweise einen schnellen, praktischen Vergleich. Dies ist das Framework, das ich am häufigsten nutze:
Web Scraping
API
Datenquelle
Sichtbarer Seiteninhalt oder gerenderter Schnittstelle
Offizieller strukturierter Endpunkt
Datenformat
Roh oder halbstrukturiert
Strukturiert und einfacher zu integrieren
Zuverlässigkeit
Anfällig für Layout- und Rendering-Änderungen
Normalerweise stabiler
Wartung
Höher
Niedriger
Compliance-Klarheit
Weniger vorhersehbar
Normalerweise klarer
Flexibilität
Hoch für öffentliche Seiten
Begrenzt auf das, was der Provider exponiert
Beste Passung
Forschung, Überwachung, einmalige Extraktion
Wiederholbare Integrationen und Publishing-Workflows
Eignung für Social Proof auf Websites
Oft zerbrechlich
Normalerweise viel besser
Der wahre Unterschied zwischen Web Scraping und API ist nicht nur, woher die Daten kommen. Es geht auch darum, wie viel Aufwand danach notwendig ist, um das System verwendbar, stabil und veröffentlichungsbereit zu halten.
Vor- und Nachteile von Web Scraping
Da eines der Haupt-Keywords hier Vor- und Nachteile von Web Scraping ist, möchte ich diesen Kompromiss deutlich zeigen, statt ihn zu vereinfachen.
Vorteile von Web Scraping
Nachteile von Web Scraping
Kann öffentliche Daten sammeln, selbst wenn keine API vorhanden ist
Funktioniert nicht, wenn sich Layouts oder Rendering ändern
Hochflexibel und anpassbar
Erfordert laufende Wartung
Nützlich für Überwachung, Forschung und Social Listening
Kann auf Anti-Bot-Systeme und Blockierung stoßen
Weniger abhängig von Provider-API-Verfügbarkeit
Datenformatierung ist oft inkonsistent
Hilfreich für leichte Experimente
Kann Richtlinien- oder Governance-Risiken in Abhängigkeit vom Anwendungsfall schaffen
Kann sichtbare Felder erfassen, die APIs möglicherweise nicht exponieren
Schwache Passung für polierte, kundenorientierte Website-Erfahrungen
Meine ehrliche Sicht ist, dass Scraping oft am stärksten ist, wenn die Ausgabe intern ist. Sobald die Ausgabe öffentlich und markenempfindlich wird, werden die Schwächen evident.
Vorteile der Verwendung von APIs
Wenn ich die Hauptvorteile der Verwendung von APIs für diesen Anwendungsfall zusammenfassen müsste:
- Saubere, strukturierte Daten: Wenn eine Marke zum Beispiel Bewertungen durch eine API einbettet und Google-Bewertungen anzeigt, kann sie Bewertungstexte, Stern-Ratings, Autorennamen und Zeitstempel in einem vorhersehbaren Format erhalten, statt sie aus unordentlichen Seitenelementen zusammenzufügen.
- Weniger Abhängigkeit von Frontend-Layouts: Wenn eine Social-Plattform zum Beispiel ihre Feed-Karten überarbeitet, kann eine API-basierte Verbindung weiterhin funktionieren, da sie sich auf den zugrunde liegenden Daten-Endpunkt stützt, statt auf die sichtbare Seitenstruktur.
- Bessere Passung für wiederholbare Workflows: Ein Multi-Location-Unternehmen kann zum Beispiel automatisch aktuelle Bewertungen von Dutzenden von Standorten in einem Dashboard sammeln, statt jede Seite einzeln zu überprüfen.
- Stärkere Unterstützung für Aktualität und Konsistenz: Eine E-Commerce-Marke kann zum Beispiel Produkt-Seiten Review-Widgets mit neuesten Kundenfeedback aktualisieren, statt die gleichen statischen Testimonials monatelang zu belassen.
- Klarere Governance und Zugriffsregeln: Ein Marketing-Team, das offizielle Integrationen nutzt, hat eine viel einfachere Zeit, zu erklären, woher der Inhalt kommt und wie er verwendet wird, als ein Team, das sich auf gescrapte öffentliche Seiten stützt.
- Weniger Bereinigung und weniger Reparaturarbeiten später: Entwickler müssen nicht ständig defekte Selektoren beheben, jedes Mal, wenn eine Quellseite seine HTML-Struktur oder Media-Rendering ändert.
- Ein einfacherer Weg von der Sammlung zur Veröffentlichung: Eine Marke kann Social Proof von verbundenen Quellen direkt in ein Live-Homepage-Karussell oder Review-Widget verschieben, ohne unzuverlässige Web-Scraping-Tools zusammenzunähen.
Kurz gesagt, APIs helfen nicht nur beim Sammeln von Daten. Sie helfen Ihnen, ein System rund um diese Daten zu bauen. Datenextraktion wird zu einem zuverlässigen Prozess, der strukturierten Datenzugriff bietet.
Außerdem ermöglichen es APIs Ihnen, Website-Seiten auszurichten, um spezifische Daten zu erhalten, anstatt alles von diesen Seiten zu scrapen und dann durch den Inhalt zu wühlen.
Warum unterscheiden sich Social-Media-Daten von allgemeinen Web-Daten?
Die meisten generischen Web-Scraping vs. API Artikel behandeln alle Online-Daten so, als würden sie in den gleichen Eimer gehören. Nach meiner Erfahrung ist hier die Analyse zu oberflächlich.
Social-Media-Inhalte sind nicht länger “nur Daten”, sobald sie auf einer Homepage, Produktseite oder im Review-Widget angezeigt werden. Zu diesem Zeitpunkt werden sie zu vertrauensaufbauendem Inhalt.
Allgemeiner Web-Daten-Anwendungsfall
Social-Media-Daten-Anwendungsfall
Oft für interne Analyse verwendet
Oft für kundenorientierte Beweise verwendet
Kleine Formatierungsfehler können akzeptabel sein
Formatierung beeinflusst direkt die Wahrnehmung
Ein vorübergehender Fehler kann unangenehm sein
Ein defekter Feed kann Vertrauen beschädigen
Normalerweise auf Abruf konzentriert
Erfordert Abruf, Moderation und Veröffentlichung
Lebt oft in Dashboards oder Berichten
Lebt auf Websites, Widgets und Conversion-Seiten
Niedriges Markenrisiko, wenn nur intern
Höheres Markenrisiko, weil Kunden es sehen
Deshalb trenne ich diese Anwendungsfälle so stark. Eine Tabelle kann unordentliche Ausgabe tolerieren. Ein Live UGC-Widget kann das nicht. Man extrahiert nicht einfach Daten von Webseiten, man implementiert diese Daten neu in vertrauensaufbauenden, Live-Website-Widgets, die automatisch aktualisiert werden.
Web Scraping von Social-Media-Daten: Wo es zusammenbricht
Der Reiz von Web Scraping für Social-Media-Daten ist anfangs offensichtlich. Öffentliche Inhalte sehen zugänglich aus, das Setup kann sich schnell anfühlen, und Teams könnten glauben, einen Shortcut gefunden zu haben.
In der Praxis beginnt das Modell auf vorhersehbare Weise zusammenzubrechen:
Frontend-Änderungen erzeugen Zerbrechlichkeit
Social-Plattformen ändern sich oft.
Ein Feed, der von sichtbarer Seitenstruktur abhängt, kann nicht mehr funktionieren, wenn eine Beschriftung anders geladen wird, ein Media-Element umstrukturiert wird oder die Plattform ändert, wie die Schnittstelle gerendert wird.
Profitipp:
Baue keinen kundenorientierten Feed nur auf Seiten-Layout-Annahmen auf. Wenn eine Plattform ändert, wie Bildunterschriften, Karten oder Media gerendert werden, kann dein Feed über Nacht zusammenbrechen. Deshalb ist offizieller API-Zugriff normalerweise die sicherere Grundlage für alles Öffentliche.
Formatierungsqualität wird schwer zu kontrollieren
Selbst wenn ein Scraper technisch funktioniert, kann die Ausgabe nicht veröffentlichungsreif sein.
Ich habe gescrapte Social-Inhalte gesehen, die mit fehlenden Bildunterschriften, schlechtem Media-Rendering, uneinheitlichen Kartenlayouts und unvollständiger Zuordnung ankamen.
Profitipp:
Ein Feed, der “technisch funktioniert”, ist nicht das gleiche wie ein Feed, der veröffentlichungsbereit ist. Bevor Inhalte live gehen, stelle sicher, dass du zuverlässig Bildunterschriften, Media-Qualität, Zuordnung, Karten-Konsistenz und Fallback-Verhalten über jedes Layout kontrollieren kannst.
Moderation wird zu einer manuellen Last
Sobald Inhalte gesammelt sind, muss immer noch jemand entscheiden, was wirklich live gehen soll.
Das bedeutet UGC-Verwaltung wie Spam-Filterung, Entfernung irrelevanter Beiträge, Ausschluss minderwertiger Inhalte und Überprüfung, ob das Endergebnis noch markenkonform wirkt.
Profitipp:
Inhaltssammlung ist nur die Hälfte der Arbeit. Der echte operative Gewinn kommt aus eingebauten UGC-Management-Workflows zum Filtern von Spam, Entfernen irrelevanter Beiträge, Präsentation der besten Inhalte und Aufrechterhaltung der Übereinstimmung aller Widgets mit deinen Markenstandards.
Skalierung vervielfacht die Wartungskosten
Ein experimenteller Feed ist verwaltbar.
Mehrere Feeds über Produktseiten, Kampagnen und Client-Websites erzeugen eine ganz andere Wartungslast. Großflächige Datensammlung braucht API-Zugriff. Wenn du Daten erhalten möchtest, zuverlässige Daten im großen Maßstab, ist direkter Zugriff auf stabile Datenverfügbarkeit wichtiger als kurzzeitige Setup-Geschwindigkeit.
Profitipp:
Ein experimenteller Feed könnte mit Scraping verwaltbar sein, aber großflächige Datensammlung ist ein anderes Spiel. Sobald du zuverlässige Inhalte über mehrere Seiten, Kampagnen oder Client-Websites benötigst, ist direkter Zugriff auf stabile Datenverfügbarkeit viel wichtiger als kurzfristige Setup-Geschwindigkeit.
Governance wird schwerer zu verwalten
Je nach Plattform, Inhaltstyp und Anwendungsfall kann Scraping zusätzliche Fragen zu Bedingungen, Datenschutz, Zugriff und Markenrisiko aufwerfen.
Für viele Teams macht diese Unsicherheit allein es zu einer schwachen Grundlage für kundenorientierte Beweise.
Profitipp:
Wenn der Inhalt Vertrauen oder Kaufentscheidungen beeinflussen wird, sollte die Sammlungsmethode nach Zuverlässigkeit und Governance beurteilt werden, nicht nur danach, ob sie die Daten einmal abrufen kann.
Direkte API vs. Aggregations-API: Was ist der Unterschied?
Dies ist die Unterscheidung, die die meisten API vs. Web-Scraping-Artikel vermissen. Viele Teams denken, die Wahl liegt einfach zwischen Scraping und der Verwendung einer API.
In Wirklichkeit ist der nützlichere Vergleich zwischen Scraping, direkter API-Integration und einer verwalteten Social-Media-Aggregator Schicht.
Was du erhältst
Hauptnachteil
Beste Passung
Web Scraping
Flexibler Zugriff auf sichtbare öffentliche Inhalte
Zerbrechlich, wartungsintensiv, ungeordnet für die Veröffentlichung
Forschung, Überwachung, Experimente
Direkte API-Integration
Offizieller strukturierter Zugriff auf Quelldaten
Man muss immer noch Moderation, Synchronisierung, Formatierung und Publishing-Logik bauen
Technische Teams mit Entwicklungsressourcen
Aggregations-API oder Plattform
Offizieller Zugriff plus Workflow, Moderation, Organisation und Publishing-Tools
Weniger rohe Kontrolle als vollständig angepasste Systeme
Marken, Marketing-Profis, Agenturen, E-Commerce-Teams
Direkter API-Zugriff ist mächtig. Aber viele Teams unterschätzen, was danach kommt. Sobald man die Daten hat, braucht man immer noch Quellenverwaltung, Moderationsregeln, Transformationslogik, Aktualisierungszyklen, Widget-Generierung, Layout-Kontrolle und laufenden Support.
Deshalb komme ich immer wieder auf den gleichen Punkt zurück: Rohzugriff ist nicht das gleiche wie eine funktionierende Social-Proof-Pipeline. Man braucht einen Social-Media-Aggregator wie EmbedSocial.
Wann macht Web Scraping immer noch Sinn?
Ich denke nicht, dass ein glaubwürdiger Artikel über Web Scraping vs. API so tun sollte, als hätte Scraping keinen Platz. Das tut es absolut. Ein gutes Beispiel ist Social Listening**.
Wenn ein Team öffentliche Gespräche überwachen, sichtbare Diskussionen erkunden oder Daten für interne Analyse sammeln möchte, kann Scraping praktisch und effizient sein.
Ein anderes Beispiel ist Nischen-Public-Datensammlung.
Manchmal sind die benötigten Informationen öffentlich, aber es existiert keine nützliche API. In solchen Fällen kann Scraping der einzige realistische Weg zu den Daten sein.
Ich denke auch, dass Scraping für leichte interne Experimente Sinn machen kann.
Wenn der Workflow temporär ist, das Team versteht die Zerbrechlichkeit und nichts Kundenorientiertes hängt davon ab, kann der Kompromiss akzeptabel sein.
Aber sobald der Inhalt Teil des öffentlichen Markenerlebnisses wird, rate ich Teams normalerweise, den Standard zu erhöhen. Hier wird Scraping oft zu einer Belastung.
Warum ist API-basierte Social Aggregation das bessere Langzeit-System für Marken?
Hier wird der Business Case viel klarer. Ein API-basiertes Aggregations-Modell ist für Marken besser, weil es mehr als nur Sammlung löst.
Es hilft, den gesamten Lebenszyklus des Inhalts nach der Sammlung zu verwalten.
Nimm eine wachsende E-Commerce-Marke als Beispiel.
Sie könnten aktuelle Bewertungen auf Produktseiten, UGC auf Landing Pages und Social Proof auf der Homepage haben. Versuche, das durch verstreute Workarounds zu pflegen, erzeugt sehr schnell Drag. Zentralisierte, API-basierte Aggregation macht dieses System verwaltbar.
Ein Service-Unternehmen ist ein anderes gutes Beispiel.
Statische Testimonial-Screenshots durch Live-Review-Inhalte zu ersetzen kann die Website aktueller, glaubwürdiger und kongruenter mit dem fühlen lassen, was Kunden gerade jetzt sagen. Stell dir eine Liebeswand auf deiner Website vor, die automatisch aktualisiert wird.
Mir ist auch wichtig, wie viel Arbeit ein System dahinter erzeugt. Ein guter Workflow reduziert Screenshots, manuelle Kurationen, wiederholte Developer-Tickets und Notfall-Fixes.
Beispiel aus meiner Arbeit bei EmbedSocial:
Ich habe Unternehmen gesehen, die einen veralteten Testimonial-Block durch einen Live-Stream aktueller Google-Bewertungen und Social-Mentions ersetzt haben. Das Ergebnis war nicht nur frischerer Inhalt. Die Website fühlte sich aktiver, aktueller und glaubwürdiger an.
Wie EmbedSocial Social Proof in ein lebendes Website-Asset verwandelt
Dies ist der Teil, den ich am direktesten aus praktischer Erfahrung kenne.
Bei EmbedSocial, geht es nicht nur darum, Marken zu helfen, Inhalte zu sammeln. Es geht darum, ihnen zu helfen, echte Kundeninhalte in etwas Organisiertes, Moderiertes und Veröffentlichungsbereites zu verwandeln.
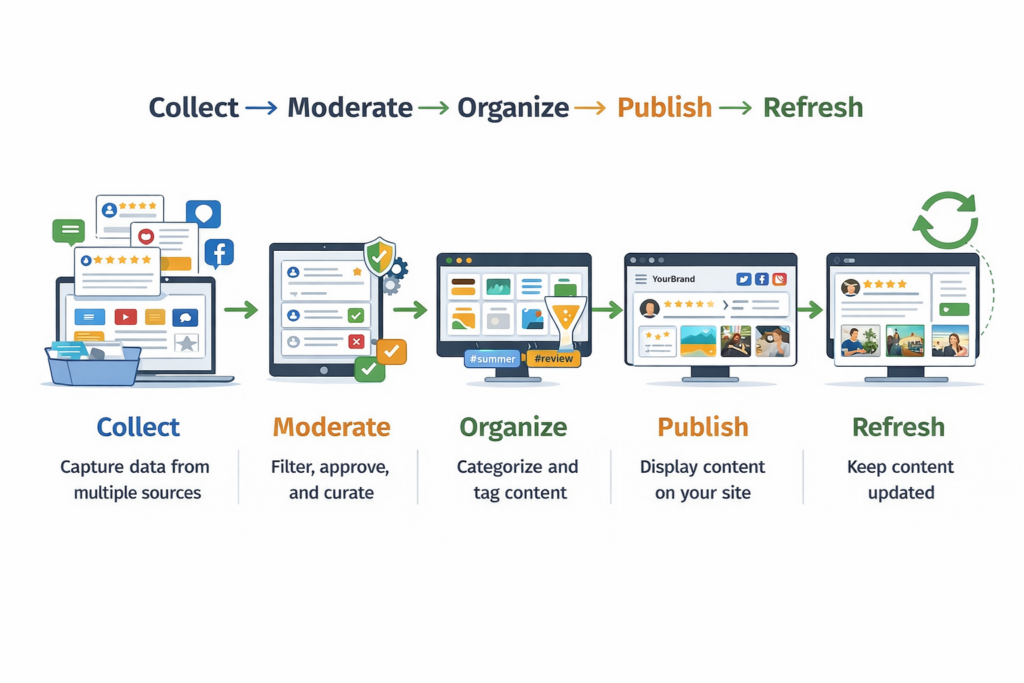
Hier ist eine einfache Grafik, die den Prozess der Aggregation von Social-Media-Inhalten abdeckt:
Und hier sind die Schritte, die du nach dem Erstellen deines EmbedSocial-Kontos durchführen musst:
Schritt 1: Sendet eine AI-Widget-Design-Anfrage
Zunächst musst du den AI-Widget-Editor auffordern, dein neues Social-Media-Widget zu erstellen:
Schritt 2: Verbinde deine Social-Media-Quellen
Dann musst du dich mit deinen sozialen Medien verbinden, um deine Inhalte in EmbedSocial zu ziehen:
Schritt 3: Entwerfe und passe dein Widget an
Dann kannst du deine Widget-Vorlage auswählen und sie weiter über AI-Anfragen anpassen:
Wenn du mit dem Widget-Design nicht zufrieden bist, gehe einfach zu AI Design und füge weitere Anfragen hinzu:
Schritt 4: Moderiere deine Widget-Inhalte
Gehe zur Moderation-Registerkarte, um bestimmte Beiträge auszuwählen, die du präsentieren möchtest:
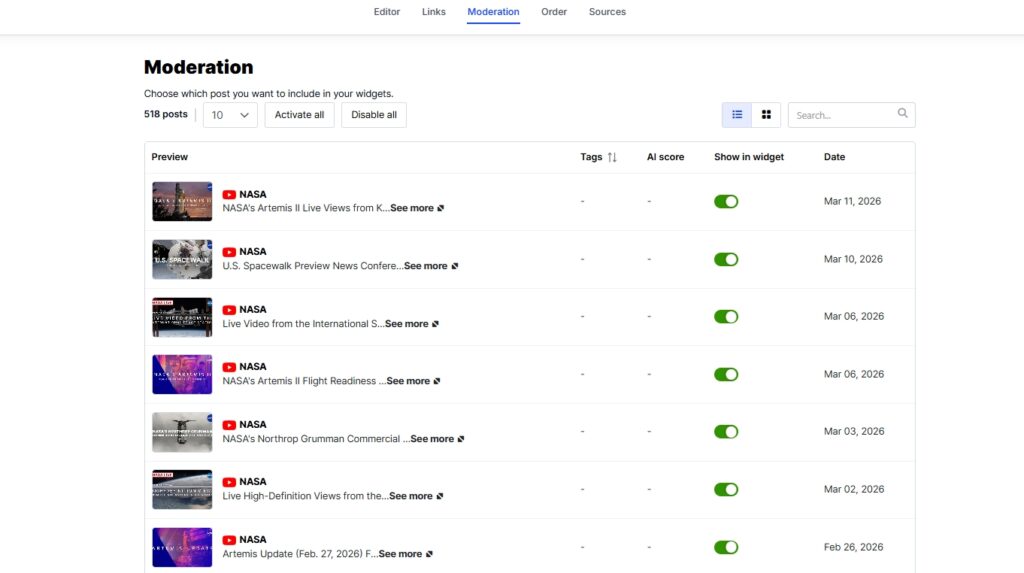
Schritt 5: Veröffentliche die Widgets auf der Website
Sobald das Widget oder der Feed bereit ist, musst du seinen Code über die Embed-Registerkarte kopieren:
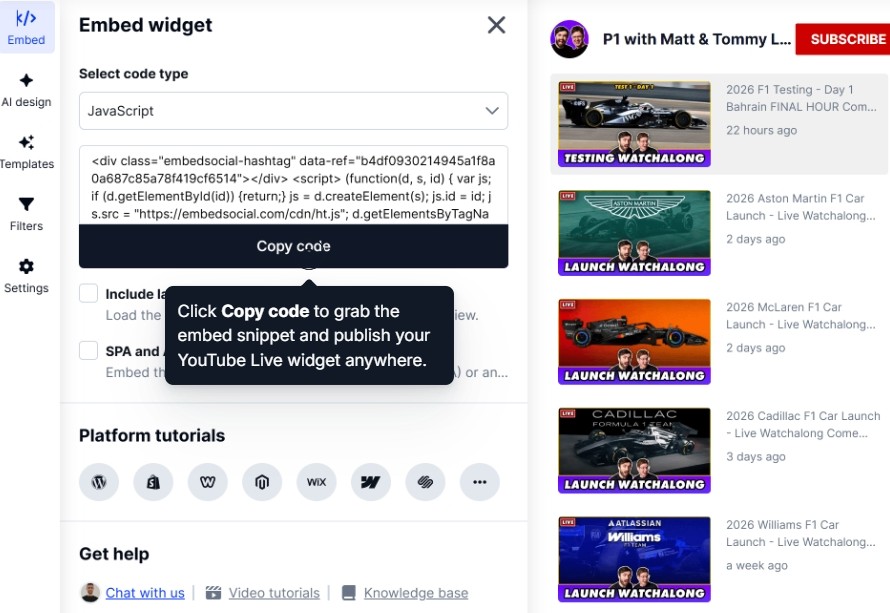
Schritt 6: Füge den Widget-Code auf deiner Website ein
Das letzte, was du tun musst, ist, zu deinem Website-Builder zu navigieren und den Widget-Code einzufügen.
So funktioniert das über alle beliebten Website-Builder:
Fazit: Verwende UGC-Plattformen mit API-Zugriff, um einen zuverlässigen Social-Proof-Workflow zu bauen!
Der Grund, warum Web Scraping vs. API eine so häufige Frage bleibt, ist einfach: beide Methoden können Online-Daten sammeln. Aber für Marken ist dieser Rahmen immer noch zu eng.
Die bessere Frage ist, wie man Social-Media-Inhalte in ein stabiles, vertrauenswürdiges, kundenorientiertes Erlebnis verwandelt, das die Website über die Zeit hinweg aktuell hält.
Aus meiner Perspektive hat Scraping immer noch einen Platz in Forschung, Überwachung und explorativer Analyse. Aber wenn das Ziel die Veröffentlichung von Social Proof auf einer Live-Website ist, ist ein API-basierter Aggregations-Workflow normalerweise die intelligentere Langzeit-Antwort.
Dieser Ansatz gibt dir mehr als nur Zugriff.
Er gibt dir Struktur, Moderation, Konsistenz und einen realistischen Weg von zerstreutem Kundeninhalt zu Live-Website-Widgets, die wirklich Vertrauen aufbauen.
FAQs zu Web Scraping vs. API für Social-Media-Inhalte
Was ist der Unterschied zwischen der Verwendung einer API und Web Scraping?
Der Hauptunterschied zwischen Web Scraping und API liegt in der Art, wie auf die Daten zugegriffen wird.
Web Scraping extrahiert Informationen aus dem, was auf einer Webseite angezeigt wird, während eine API strukturierte Daten über einen offiziellen Zugriffspunkt bereitstellt, der für Software-Integration konzipiert ist.
Ist die Verwendung einer API besser als Web Scraping?
Wenn Teams API vs. Web Scraping vergleichen, hängt die Antwort vom Anwendungsfall ab.
Für Forschung oder einmalige Überwachung kann Scraping Sinn machen. Für wiederholbare Workflows und kundenorientierte Website-Inhalte sind APIs normalerweise die stärkere Wahl.
Was ist Web Scraping in einfachen Worten?
Wenn ich Web Scraping in einem Satz beantworten müsste, würde ich sagen, es ist der Prozess, automatisch sichtbare Informationen von Webseiten zu sammeln und sie in strukturierte Daten umzuwandeln.
Deshalb wird es oft in Überwachungs-, Public-Data-Sammlungs- und Forschungs-Workflows verwendet.
Wie funktioniert Web Scraping Schritt für Schritt?
Auf einer grundlegenden Ebene folgt, wie Web Scraping funktioniert, einer Abfolge.
Ein Scraper fordert eine Seite an, liest den HTML- oder gerenderten Inhalt, identifiziert die Zielelemente, extrahiert die benötigten Felder und speichert sie in einem strukturierten Format wie JSON oder CSV.
Was sind die Vor- und Nachteile von Web Scraping?
Die Haupt-Vor- und Nachteile von Web Scraping kommen auf Flexibilität gegenüber Zuverlässigkeit herunter.
Scraping ist flexibel, weil es öffentliche Daten sammeln kann, selbst wenn keine API vorhanden ist, aber es ist auch zerbrechlicher, wartungsintensiver und normalerweise eine schwächere Passung für kundenorientierte Website-Erfahrungen.
Was sind die Hauptvorteile der Verwendung von APIs?
Die Hauptvorteile der Verwendung von APIs sind Struktur, Konsistenz und Wiederholbarkeit.
APIs geben normalerweise saubere Daten zurück, sind weniger abhängig von Frontend-Seitenänderungen und lassen sich einfacher mit Langzeit-Workflows verbinden.
Kannst du Web Scraping für Social-Media-Daten verwenden?
Ja, Web Scraping von Social-Media-Daten ist in einigen Situationen möglich.
Aber nach meiner Erfahrung ist es viel weniger zuverlässig, wenn das Ziel darin besteht, diesen Inhalt auf einer Live-Website zu veröffentlichen, wo Formatierung, Aktualität und Moderation alle wichtig sind.
Warum funktionieren gescrapte Social Feeds so oft nicht?
Gescrapte Feeds funktionieren oft nicht, weil sie von der Seitenstruktur abhängen.
Wenn eine Plattform ändert, wie Bildunterschriften, Thumbnails, Media-Karten oder andere Elemente gerendert werden, kann der Scraper aufhören, vollständige oder konsistente Daten zurückzugeben.
Wann macht Web Scraping immer noch Sinn?
Web Scraping macht immer noch Sinn für Forschung, Social Listening, Public-Data-Sammlung und einige interne Experimente.
Ich werde viel vorsichtiger, wenn der Inhalt für ein kundenorientiertes Markenerlebnis bestimmt ist.
Was ist der Unterschied zwischen einer direkten API und einer Aggregations-Plattform?
Eine direkte API gibt dir Rohzugriff auf Quelldaten.
Eine Aggregations-Plattform nimmt diesen Zugriff und verwandelt ihn in einen verwendbaren Workflow, indem sie dir hilft, Inhalte über mehrere Quellen zu sammeln, zu moderieren, zu organisieren und zu veröffentlichen.
Kann ich Social-Media-Inhalte auf meiner Website anzeigen, ohne zu scrapen?
Ja.
Tatsächlich ist das für die meisten Marken der bessere Weg. Ein API-basierter Aggregations-Workflow lässt dich Social Proof durch offizielle Verbindungen sammeln und über Widgets, Karussels, Galerien oder Review-Feeds veröffentlichen, ohne dich auf brüchige Scraping-Methoden zu verlassen.
Ist Web Scraping billiger als APIs?
Nicht unbedingt.
Scraping kann anfangs billiger aussehen, aber die Langzeit-Wartungslast ändert oft das Kostenbild, sobald Fixes, Überwachung, Formatierungsfehler und öffentliche Funktionsausfälle hinzukommen.
Ist API-basierte Social-Media-Aggregation besser für Marken?
Für die meisten Marken ja.
Wenn das Ziel darin besteht, eine Website mit vertrauenswürdigen Kundeninhalten aktuell zu halten, ist API-basierte Aggregation normalerweise das bessere Langzeit-System, da es Sammlung, Moderation und Veröffentlichung in einem Workflow unterstützt.
![11 beste Social-Media-Widgets für Websites [+Top-Anwendungsfälle]](https://embedsocial.com/wp-content/uploads/2023/11/embedsocial-ugc-software-landing-page-1024x688.jpg)
![Wie man Testimonials auf einer Website einbettet 2026 [2 Methoden + Tipps]](https://embedsocial.com/wp-content/uploads/2024/09/embed-trustpilot-reviews-step-01-use-ai-to-describe-your-widget-1024x576.webp)
![Video-Galerie auf Websites einbetten [+ 5 Widget-Vorlagen]](https://embedsocial.com/wp-content/uploads/2026/02/youtube-channel-section.jpg)