In EmbedSocial, vedo lo stesso schema ancora e ancora: i brand sono circondati da prove da parte dei clienti, eppure i loro siti web si affidano ancora a testimonianze obsolete, screenshot manuali o feed di social media obsoleti che non riflettono più quello che i clienti dicono oggi.
Questo è il motivo per cui il dibattito tra web scraping vs API è così importante nel mio lavoro.
Sulla carta, entrambi i metodi possono raccogliere dati online. In pratica, creano risultati molto diversi quando l’obiettivo è pubblicare recensioni fresche, UGC, e prove sociali su un sito web in tempo reale.
Ho visto team iniziare con una soluzione veloce, solo per scoprire che la vera sfida non è raccogliere contenuti generati dagli utenti una volta.
La vera sfida è aggregare e incorporare i post dei social media in modo affidabile, moderarli adeguatamente e usarli per diventare più affidabili.
Bene, di seguito spiego cos’è il web scraping, mostro come funziona il web scraping, analizzo la differenza tra web scraping e API, e spiego perché l’aggregazione sociale basata su API come quella di EmbedSocial è di solito il modello a lungo termine migliore per i brand.
Prima di approfondire, ecco il riassunto:
Cos’è il web scraping?
Se qualcuno mi chiede cos’è il web scraping, la mia risposta più semplice è questa:
È il processo di estrazione delle informazioni visibili da una pagina web e la loro conversione in dati strutturati. Uno scraper visita una pagina, legge ciò che è visualizzato nell’HTML o nell’interfaccia renderizzata, identifica gli elementi che desidera e salva quell’informazione in un formato più utilizzabile.
Definizione di ‘web scraping’
Queste informazioni possono includere testo di recensioni, nomi utente, didascalie, valutazioni, dettagli prodotto, URL di immagini, timestamp o altri dati pubblici.
Questo è il motivo per cui lo scraping è popolare nei flussi di lavoro con un’elevata densità di ricerca. Le aziende possono estrarre dati per casi di uso di ascolto sociale, come il monitoraggio dei concorrenti, l’analisi pubblica delle recensioni, il monitoraggio dei prezzi e, in alcuni casi, lo scraping dei dati dei social media.
Voglio essere giusto qui: lo scraping non è intrinsecamente sbagliato o inutile.
Può essere pratico quando non esiste un’API adatta, o quando l’obiettivo è l’analisi interna piuttosto che la pubblicazione rivolta ai clienti.
Il problema inizia quando i team assumono che un metodo costruito per l’estrazione sia automaticamente buono per le operazioni di contenuto del sito web in corso.
Dalla mia esperienza, è qui che le cose iniziano a rompersi.
Come funziona il web scraping?
La maggior parte delle spiegazioni su come funziona il web scraping rimangono troppo astratte. Penso che sia molto più chiaro quando lo guardi come un processo passo dopo passo:
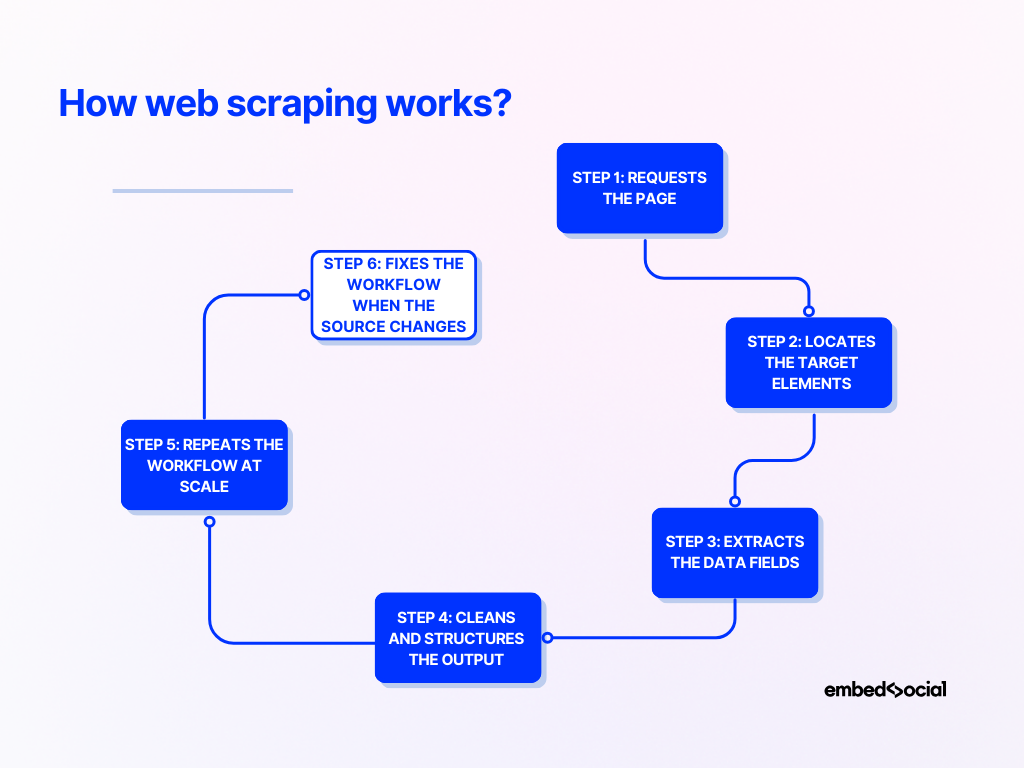
Passaggio 1: Richiede la pagina
Uno scraper prima invia una richiesta al sito web di destinazione e recupera il contenuto della pagina.
Nei casi semplici, questo significa scaricare HTML grezzo. Nei casi più difficili, potrebbe essere necessario renderizzare JavaScript o simulare una sessione del browser.
Passaggio 2: Individua gli elementi target
Successivamente, lo scraper scansiona la struttura della pagina per i dati di cui ha bisogno.
Potrebbe fare affidamento su selettori CSS, nomi di classi, ID di elementi, percorsi XPath o componenti ripetuti per trovare i blocchi di contenuto giusti.
Passaggio 3: Estrae i campi dati
Una volta individuati gli elementi target, lo scraper estrae i campi utili.
Questo può includere didascalie, valutazioni, nomi degli autori, hashtag, link multimediali, date, testo di recensione o altri attributi visibili.
Passaggio 4: Pulisce e struttura l’output
I dati scrapati sono spesso disordinati.
Quindi il passaggio successivo è normalizzare le date, rimuovere i caratteri extra, ristrutturare i campi e convertire tutto in un formato strutturato come JSON o CSV.
Passaggio 5: Ripete il flusso di lavoro su larga scala
Se l’obiettivo è la raccolta in corso, lo scraper viene eseguito ripetutamente su più pagine, profili, feed o URL di origine. Questo è dove inizia a comparire l’onere della manutenzione.
Passaggio 6: Corregge il flusso di lavoro quando l’origine cambia
Uno scraper dipende dalla struttura della pagina. Se la piattaforma di origine cambia il modo in cui didascalie, miniature o elementi della pagina vengono caricati, il flusso di lavoro potrebbe non riuscire. Tale errore potrebbe essere minore in un rapporto interno, ma è molto più serio quando il risultato appare su un sito web pubblico.
In tal caso, è necessario regolare lo scraper.
Esempio reale:
Ho visto un feed di contenuti social funzionare perfettamente nei test, poi degradarsi silenziosamente dopo che una piattaforma aveva cambiato il modo in cui le schede multimediali venivano renderizzate. Il team non ha solo perso la qualità dei dati. Hanno finito con un’esperienza di sito web interrotta.
Cos’è un’API?
Un’API, o interfaccia di programmazione delle applicazioni, è un modo ufficiale per un sistema di richiedere dati da un altro in un formato strutturato.
Definizione di ‘API’
Quella definizione sembra tecnica, ma la differenza pratica è semplice.
Con lo scraping, leggi quello che appare sulla pagina. Con un’API, richiedi dati attraverso un canale costruito per l’accesso al software.
Invece di analizzare il contenuto front-end visibile, ricevi dati strutturati direttamente da endpoint definiti, spesso in JSON.
Questo di solito rende il flusso di lavoro più facile da mantenere.
I dati sono più puliti, la struttura è più prevedibile, e l’integrazione è meno dipendente dall’aspetto di una pagina nel browser.
Certo, le API non sono perfette. Possono avere limiti, approvazioni, quote e regole controllate dal provider su quali dati sono disponibili.
Ma per flussi di lavoro ricorrenti, soprattutto quelli legati a un sito web in tempo reale, le API sono di solito una base operativa molto più forte.
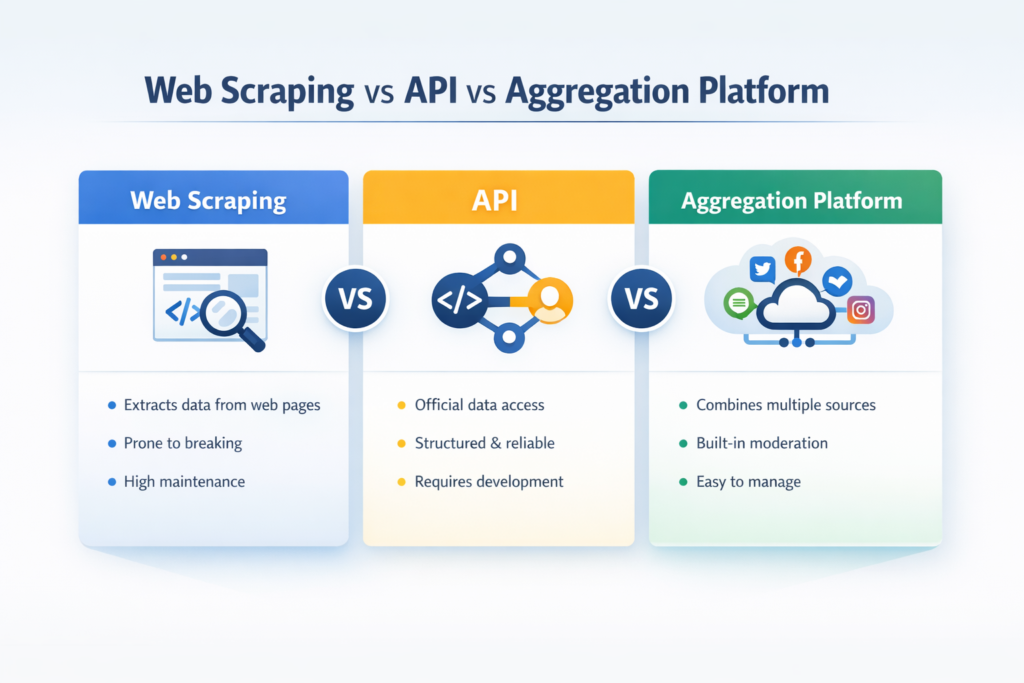
Web scraping vs API: le differenze chiave a colpo d’occhio
Quando le persone cercano API vs web scraping o web scraping vs. API, di solito vogliono un confronto veloce e pratico. Questo è il framework che uso più spesso:
Web scraping
API
Fonte di dati
Contenuto della pagina visibile o interfaccia renderizzata
Endpoint strutturato ufficiale
Formato dati
Grezzo o semi-strutturato
Strutturato e più facile da integrare
Affidabilità
Vulnerabile ai cambiamenti di layout e rendering
Di solito più stabile
Manutenzione
Più alta
Più bassa
Chiarezza di conformità
Meno prevedibile
Di solito più chiara
Flessibilità
Alta per le pagine pubbliche
Limitata a quello che il provider espone
Miglior adattamento
Ricerca, monitoraggio, estrazione una tantum
Flussi di lavoro di integrazione e pubblicazione ripetibili
Adattamento per la prova sociale sui siti web
Spesso fragile
Di solito molto migliore
La vera differenza tra web scraping e API non è solo da dove provengono i dati. È anche quanto sforzo viene dopo la raccolta per mantenere il sistema utilizzabile, stabile e pronto per la pubblicazione.
Pro e contro del web scraping
Poiché una delle parole chiave principali qui è pro e contro del web scraping, voglio mostrare chiaramente il compromesso piuttosto che semplificarlo eccessivamente.
Pro del web scraping
Contro del web scraping
Può raccogliere dati pubblici anche quando non esiste un’API
Si interrompe quando i layout o il rendering cambiano
Altamente flessibile e personalizzabile
Richiede manutenzione continua
Utile per il monitoraggio, la ricerca e l’ascolto sociale
Può affrontare sistemi anti-bot e blocchi
Meno dipendente dalla disponibilità dell’API del provider
La formattazione dei dati è spesso incoerente
Utile per esperimenti leggeri
Può creare rischi di policy o governance a seconda del caso d’uso
Può acquisire campi visibili che le API potrebbero non esporre
Adatto debole per esperienze di siti web polacche rivolte ai clienti
La mia visione onesta è che lo scraping è spesso più forte quando l’output è interno. Una volta che l’output diventa pubblico e sensibile al brand, i punti deboli diventano evidenti.
Vantaggi dell’uso delle API
Se dovessi riassumere i principali vantaggi dell’uso delle API per questo caso d’uso:
- Dati più puliti e strutturati: ad esempio, quando un brand estrae e incorpora le recensioni di Google attraverso un’API, può ricevere testo di recensione, valutazioni in stelle, nomi degli autori e timestamp in un formato prevedibile invece di metterli insieme da elementi di pagina disordinati;
- Minore dipendenza dai layout front-end: ad esempio, se una piattaforma social riprogetta le sue schede di feed, una connessione basata su API può continuare a funzionare perché si basa sull’endpoint di dati sottostante piuttosto che sulla struttura della pagina visibile;
- Migliore adattamento per flussi di lavoro ripetibili: ad esempio, un’attività con più sedi può raccogliere automaticamente recensioni fresche da dozzine di sedi in un’unica dashboard invece di controllare manualmente ogni pagina una per una;
- Supporto più forte per la freschezza e la coerenza: ad esempio, un brand di e-commerce può mantenere i widget di revisione della pagina di prodotto aggiornati con i feedback recenti dei clienti invece di lasciare le stesse testimonianze statiche in posizione per mesi;
- Regole di governance e accesso più chiare: ad esempio, un team di marketing che utilizza integrazioni ufficiali ha un momento molto più facile nel spiegare da dove proviene il contenuto e come viene utilizzato rispetto a un team che fa affidamento su pagine pubbliche scrapate;
- Meno pulizia e meno lavori di riparazione in seguito: ad esempio, gli sviluppatori non devono continuare a correggere i selettori interrotti ogni volta che un sito di origine cambia la sua struttura HTML o il rendering multimediale;
- Un percorso più semplice dalla raccolta alla pubblicazione: ad esempio, un brand può spostare la prova sociale da fonti connesse a un carosello della homepage in tempo reale o a un widget di revisione senza cucire insieme strumenti di scraping web inaffidabili.
In breve, le API non solo ti aiutano a raccogliere dati. Ti aiutano a costruire un sistema attorno a quei dati. L’estrazione dei dati diventa un processo affidabile che fornisce accesso ai dati strutturati.
Inoltre, le API ti permettono di mirare a pagine di siti web per ottenere dati specifici invece di scrapare tutto da detto pagine e poi setacciare i contenuti.
Perché i dati dei social media sono diversi dai dati web generali?
La maggior parte degli articoli generici web scraping vs API trattano tutti i dati online come se appartenessero allo stesso contenitore. Dalla mia esperienza, è qui che l’analisi diventa troppo superficiale.
Il contenuto dei social media smette di essere “solo dati” nel momento in cui appare su una homepage, pagina di prodotto o widget di revisione. A quel punto, diventa contenuto per costruire la fiducia.
Caso d’uso dei dati web generali
Caso d’uso dei dati dei social media
Spesso usato per l’analisi interna
Spesso usato per la prova rivolta ai clienti
I problemi di formattazione minori possono essere accettabili
La formattazione influisce direttamente sulla percezione
Un’interruzione temporanea può essere scomoda
Un feed rotto può danneggiare la fiducia
Di solito focalizzato sul recupero
Richiede recupero, moderazione e pubblicazione
Spesso vive in dashboard o report
Vive su siti web, widget e pagine di conversione
Rischio di brand inferiore se solo interno
Rischio di brand superiore perché i clienti lo vedono
Questo è il motivo per cui separo così fortemente questi casi d’uso. Un foglio di calcolo può tollerare output disordinato. Un widget UGC in tempo reale non può. Non estrai solo dati da pagine web, li re-implementi in widget per la fiducia in tempo reale rivolti ai clienti che si aggiornano automaticamente.
Web scraping dati dei social media: Dove si interrompe?
L’appello del web scraping dei dati dei social media è ovvio all’inizio. Il contenuto pubblico sembra accessibile, la configurazione può sembrare veloce e i team potrebbero credere di aver trovato una scorciatoia.
In pratica, il modello inizia a rompersi in modi prevedibili:
I cambiamenti front-end creano fragilità
Le piattaforme social cambiano spesso.
Un feed che dipende dalla struttura della pagina visibile può smettere di funzionare quando una didascalia viene caricata diversamente, un elemento multimediale viene ristrutturato o la piattaforma cambia il modo in cui l’interfaccia viene renderizzata.
Consiglio professionale:
Non costruire mai un feed rivolto ai clienti sulla base solo di ipotesi di layout di pagina. Se una piattaforma cambia il modo in cui didascalie, schede o contenuti multimediali vengono renderizzati, il tuo feed può interrompersi dall’oggi al domani. Ecco perché l’accesso ufficiale alle API è di solito la base più sicura per qualsiasi cosa rivolta al pubblico.
La qualità della formattazione diventa difficile da controllare
Anche quando uno scraper funziona tecnicamente, l’output potrebbe non essere idoneo per la pubblicazione.
Ho visto contenuti social scrapati arrivare con didascalie mancanti, cattiva renderizzazione multimediale, layout di schede irregolari e attribuzione incompleta.
Consiglio professionale:
Un feed che “funziona tecnicamente” non è la stessa cosa di un feed pronto per la pubblicazione. Prima che il contenuto diventi in tempo reale, assicurati di poter controllare in modo affidabile didascalie, qualità multimediale, attribuzione, coerenza delle schede e comportamento di fallback in ogni layout.
La moderazione diventa un onere manuale
Una volta raccolto il contenuto, qualcuno deve comunque decidere cosa dovrebbe effettivamente diventare in tempo reale.
Questo significa gestione UGC come filtrare lo spam, rimuovere i post irrilevanti, escludere contenuti di bassa qualità e verificare se il risultato finale mantiene ancora un’aria di marca.
Consiglio professionale:
La raccolta di contenuti è solo metà del lavoro. Il vero vantaggio operativo viene dall’avere flussi di lavoro di gestione UGC incorporati per filtrare lo spam, rimuovere post irrilevanti, mettere in risalto i migliori contenuti e mantenere ogni widget allineato con gli standard del tuo brand.
La scala moltiplica il costo della manutenzione
Un feed sperimentale è gestibile.
Più feed su pagine di prodotto, campagne e siti web client creano un onere di manutenzione molto diverso. La raccolta dati affidabile su larga scala necessita di accesso API. Se desideri ottenere dati, dati affidabili su larga scala, l’accesso diretto alla disponibilità di dati stabile è molto più importante della velocità di configurazione a breve termine.
Consiglio professionale:
Un feed sperimentale potrebbe essere gestibile con lo scraping, ma la raccolta dati su larga scala è un gioco diverso. Una volta che hai bisogno di contenuti affidabili su più pagine, campagne o siti client, l’accesso diretto alla disponibilità di dati stabili è molto più importante che velocità di configurazione a breve termine.
La governance diventa più difficile da gestire
A seconda della piattaforma, del tipo di contenuto e del caso d’uso, lo scraping può sollevare domande extra su termini, privacy, accesso e rischio di brand.
Per molti team, quell’incertezza da sola la rende una base debole per la prova rivolta ai clienti.
Consiglio professionale:
Se il contenuto influenzerà le decisioni di fiducia o acquisto, il metodo di raccolta dovrebbe essere giudicato dall’affidabilità e dalla governance, non solo dal fatto che possa estrarre i dati una volta.
API diretta vs API di aggregazione: qual è la differenza?
Questa è la distinzione che la maggior parte degli articoli API vs web scraping manca. Molti team pensano che la scelta sia semplicemente tra scraping e l’uso di un’API.
In realtà, il confronto più utile è tra scraping, integrazione API diretta e un livello aggregatore di social media gestito.
Quello che ottieni
Principale svantaggio
Miglior adattamento
Web scraping
Accesso flessibile al contenuto pubblico visibile
Fragile, pesante in termini di manutenzione, disordinato per la pubblicazione
Ricerca, monitoraggio, esperimenti
Integrazione API diretta
Accesso strutturato ufficiale ai dati di origine
Devi comunque costruire moderazione, sincronizzazione, formattazione e logica di pubblicazione
Team tecnici con risorse di sviluppo
API di aggregazione o piattaforma
Accesso ufficiale più flusso di lavoro, moderazione, organizzazione e strumenti di pubblicazione
Meno controllo grezzo rispetto ai sistemi completamente personalizzati
Brand, marketer, agenzie, team di e-commerce
L’accesso API diretto è potente. Ma molti team sottovalutano cosa viene dopo la connettività. Una volta che hai i dati, hai ancora bisogno della gestione delle fonti, delle regole di moderazione, della logica di trasformazione, dei cicli di aggiornamento, della generazione di widget, del controllo del layout e della manutenzione continua.
Questo è il motivo per cui continuo a tornare allo stesso punto: l’accesso grezzo non è lo stesso di una pipeline di prova sociale che funziona. Hai bisogno di un aggregatore di social media come EmbedSocial.
Quando il web scraping ha ancora senso?
Non penso che un articolo credibile su web scraping vs. API dovrebbe pretendere che lo scraping non abbia posto. Ha assolutamente un posto. Un buon esempio è l’ascolto sociale.
Se un team vuole monitorare conversazioni pubbliche, esplorare discussioni visibili o raccogliere dati per analisi interne, lo scraping può essere pratico ed efficiente.
Un altro esempio è la raccolta di dati pubblica di nicchia.
A volte le informazioni necessarie sono pubbliche, ma non esiste un’API utile. In questi casi, lo scraping potrebbe essere l’unico percorso realistico verso i dati.
Penso anche che lo scraping possa avere senso per esperimenti interni leggeri.
Se il flusso di lavoro è temporaneo, il team comprende la fragilità e nulla rivolo al cliente dipende da esso, il compromesso potrebbe essere accettabile.
Ma una volta che il contenuto diventa parte dell’esperienza del brand pubblico, di solito consiglio ai team di aumentare lo standard. È qui che lo scraping spesso inizia a diventare una passività.
Perché l’aggregazione sociale basata su API è il sistema a lungo termine migliore per i brand?
Questo è dove il caso aziendale diventa molto più chiaro. Un modello di aggregazione basato su API è migliore per i brand perché risolve più della raccolta.
Aiuta a gestire l’intero ciclo di vita del contenuto dopo la raccolta.
Prendi un brand di e-commerce in crescita come esempio.
Potrebbe volere recensioni recenti sulle pagine di prodotto, UGC sulle pagine di destinazione e prove sociali sulla homepage. Cercare di mantenere tutto attraverso soluzioni alternative sparse crea attrito molto rapidamente. L’aggregazione centralizzata basata su API rende il sistema gestibile.
Un’azienda di servizi è un altro buon esempio.
Sostituire le schermate di testimonianze statiche con contenuti di revisione in tempo reale può far sentire il sito più attuale, più credibile e più allineato con quello che i clienti stanno dicendo in questo momento. Immagina una pagina wall-of-love sul tuo sito web che si aggiorna automaticamente.
Mi importa anche di quanto lavoro crea un sistema dietro le quinte. Un buon flusso di lavoro riduce gli screenshot, la cura manuale, i ticket degli sviluppatori ripetitivi e le correzioni di emergenza.
Esempio dal mio lavoro su EmbedSocial:
Ho visto aziende sostituire un blocco di testimonianza obsoleto con un flusso in tempo reale di recensioni recenti di Google e menzioni social. Il risultato non era solo contenuto più fresco. Il sito si sentiva più attivo, più attuale e più credibile.
Come EmbedSocial trasforma la prova sociale in un asset di sito web vivo?
Questa è la parte che conosco più direttamente dall’esperienza pratica.
Su EmbedSocial, l’obiettivo non è solo aiutare i brand a raccogliere contenuti. È aiutarli a trasformare i veri contenuti dei clienti in qualcosa di organizzato, moderato e pronto per la pubblicazione.
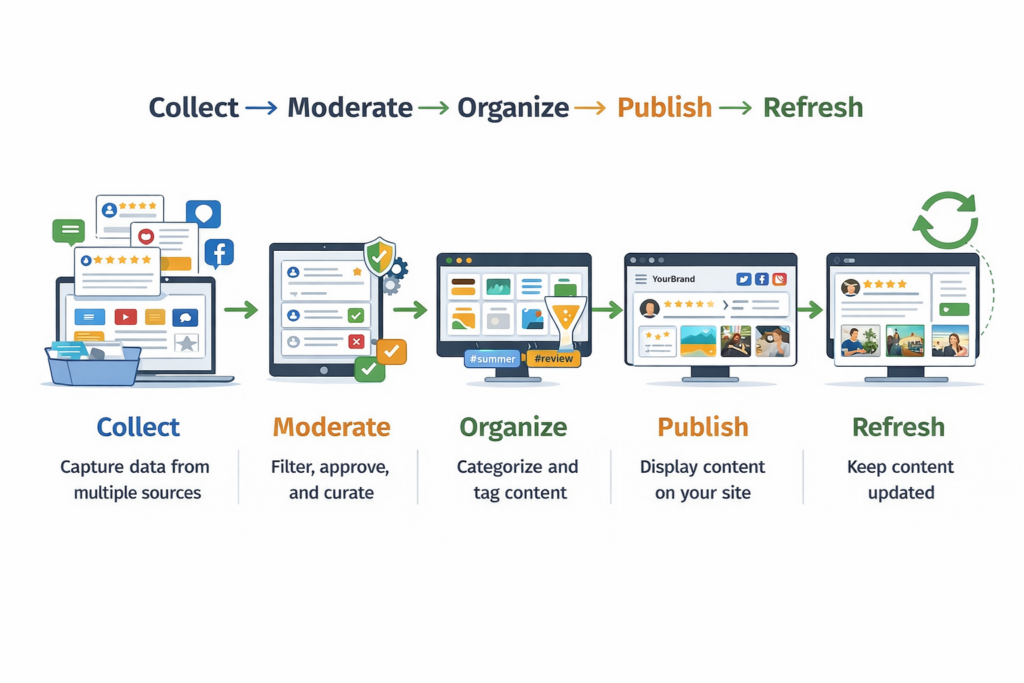
Ecco una grafica semplice che copre il processo di aggregazione del contenuto dei social media:
E questi sono i passaggi che devi completare dopo aver creato il tuo account EmbedSocial:
Passaggio 1: Invia un prompt di design di widget AI
Per prima cosa, devi richiedere all’editor di widget AI di creare il tuo nuovo widget di social media:
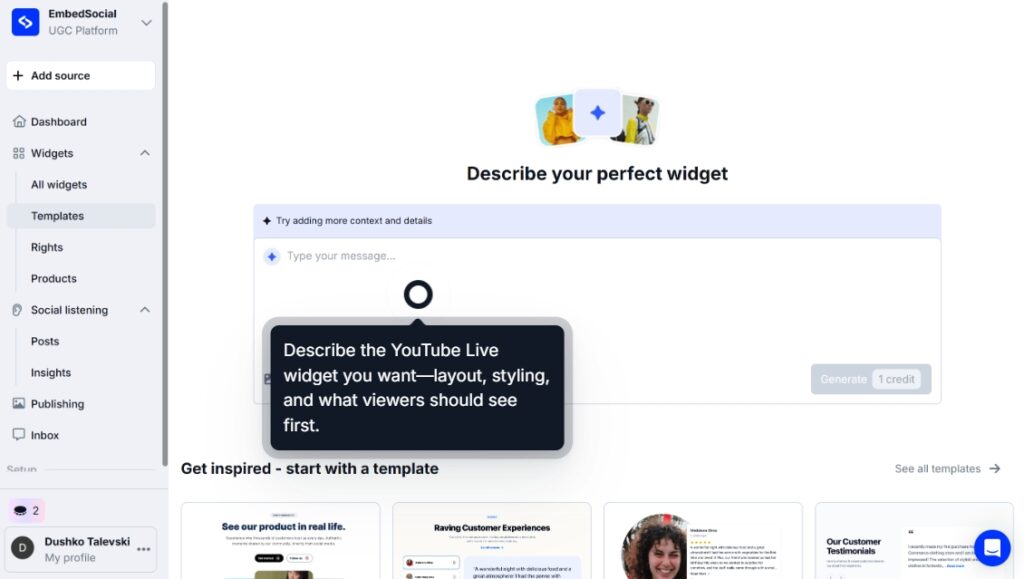
Passaggio 2: Connetti le tue fonti di social media
Quindi, devi connetterti ai tuoi social media per estrarre i loro contenuti in EmbedSocial:
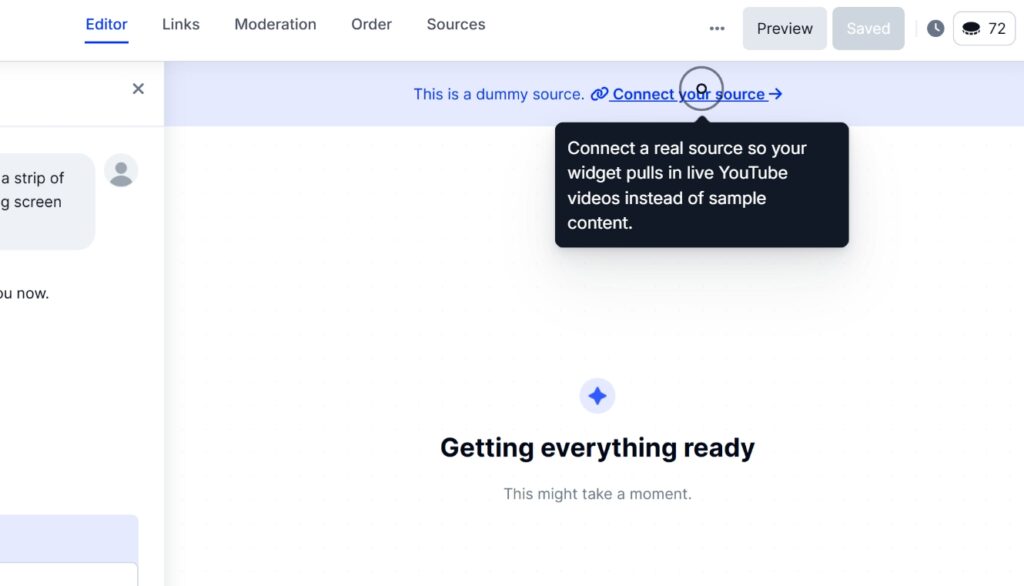
Passaggio 3: Progetta e personalizza il tuo widget
Quindi, puoi selezionare il modello di widget e personalizzarlo ulteriormente tramite prompt AI:
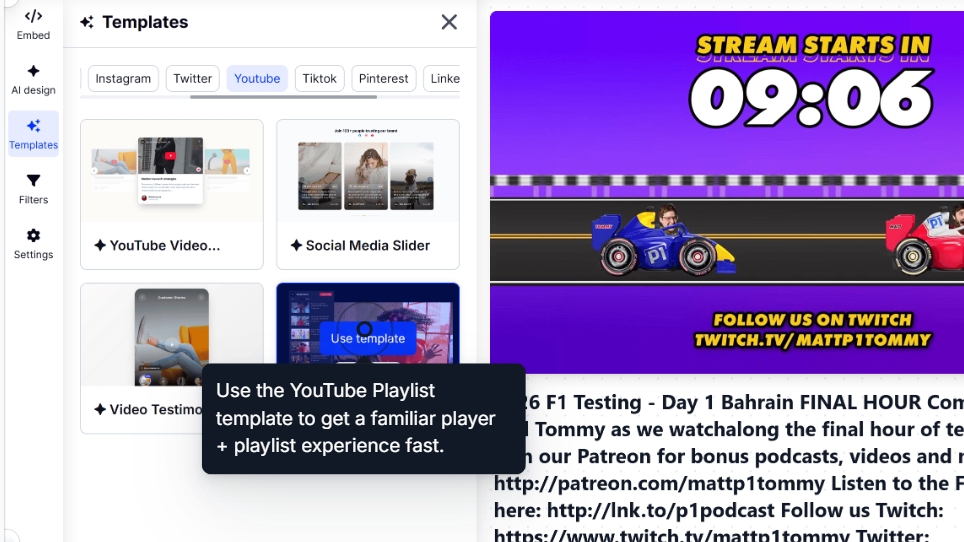
Se non sei soddisfatto dell’aspetto del widget, semplicemente naviga verso il design AI e aggiungi ulteriori prompt:
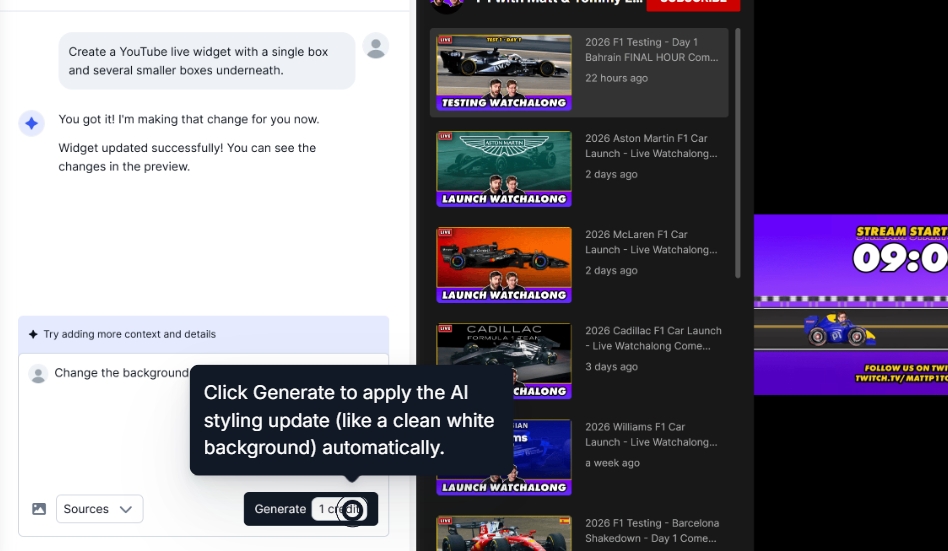
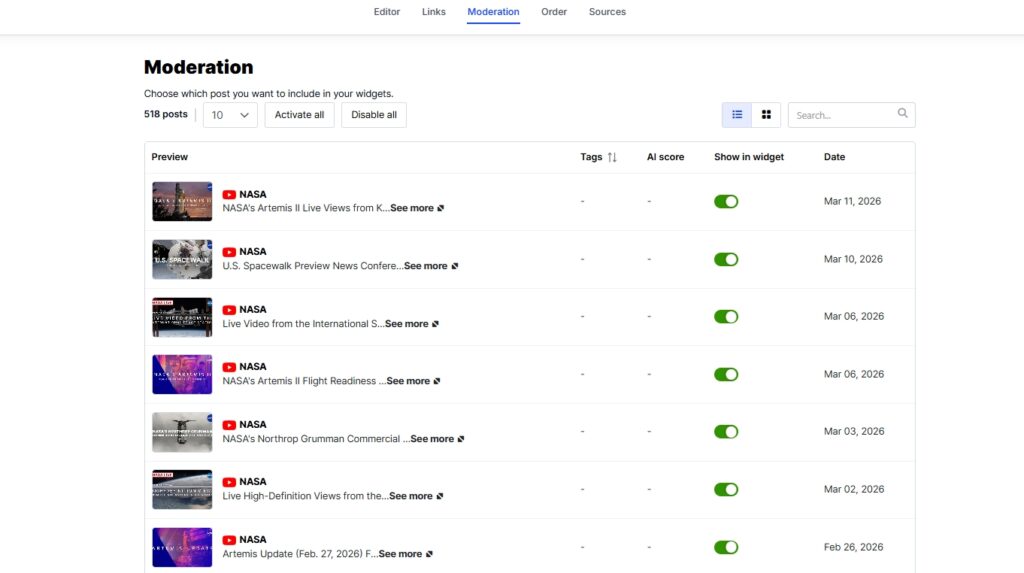
Passaggio 4: Modera il contenuto del tuo widget
Dirigiti alla scheda Moderazione per selezionare i post specifici che desideri mettere in risalto:
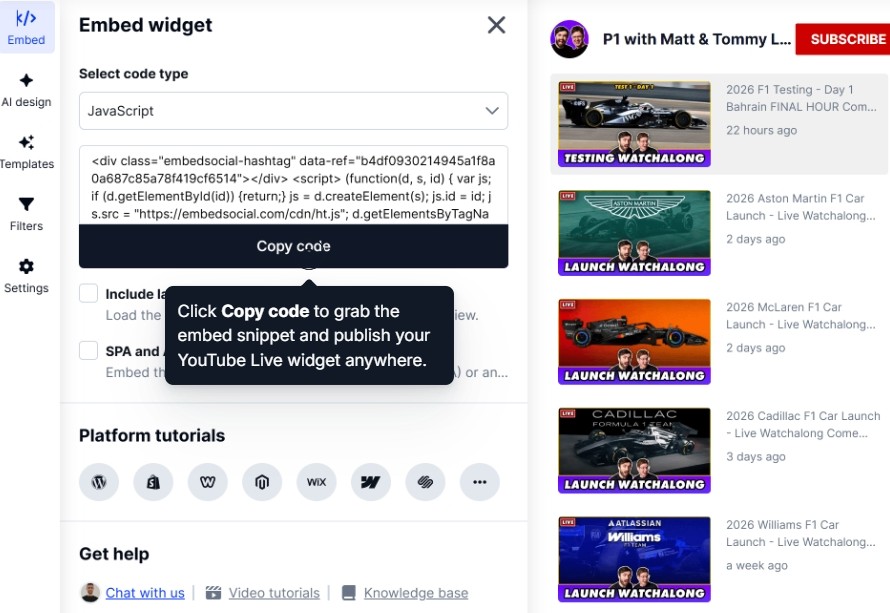
Passaggio 5: Pubblica i widget sul sito web
Una volta che il widget o il feed è pronto, devi copiare il suo codice incorporabile tramite la scheda Incorpora:
Passaggio 6: Incolla il codice del widget sul tuo sito web
L’ultima cosa che devi fare è navigare verso il tuo builder di siti web e incollare il codice del widget.
Ecco come funziona su tutti i builder di siti web più popolari:
Conclusione: Usa piattaforme UGC con accesso API per costruire un flusso di lavoro affidabile di prove sociali!
Il motivo per cui web scraping vs API rimane una domanda così comune è semplice: entrambi i metodi possono aiutare a raccogliere dati online. Ma per i brand, questo framing è comunque troppo stretto.
La domanda migliore è come trasformare il contenuto dei social media in un’esperienza coerente e affidabile rivolta ai clienti che mantiene il sito web fresco nel tempo.
Dalla mia prospettiva, lo scraping ha ancora un posto nella ricerca, nel monitoraggio e nell’analisi esplorativa. Ma quando l’obiettivo è pubblicare la prova sociale su un sito web in tempo reale, un flusso di lavoro di aggregazione basato su API è di solito la risposta più intelligente a lungo termine.
Questo approccio ti dà più che accesso.
Ti dà struttura, moderazione, coerenza e un percorso realistico dai contenuti dei clienti sparsi ai widget del sito web in tempo reale che costruiscono effettivamente fiducia.
Domande frequenti su web scraping vs API per il contenuto dei social media
Qual è la differenza tra l’utilizzo di un’API e il web scraping?
La principale differenza tra web scraping e API è il modo in cui i dati vengono accessibili.
Il web scraping estrae informazioni da quello che appare su una pagina web, mentre un’API fornisce dati strutturati attraverso un punto di accesso ufficiale progettato per l’integrazione del software.
L’utilizzo di un’API è meglio del web scraping?
Quando i team confrontano API vs web scraping, la risposta dipende dal caso d’uso.
Per la ricerca o il monitoraggio una tantum, lo scraping può avere senso. Per flussi di lavoro ripetibili e contenuti di siti web rivolti ai clienti, le API sono di solito la scelta più forte.
Che cos’è il web scraping in termini semplici?
Se dovessi rispondere cosa sia il web scraping in una frase, direi che è il processo di raccolta automatica di informazioni visibili da pagine web e la loro trasformazione in dati strutturati.
Questo è il motivo per cui è spesso usato nei flussi di lavoro di monitoraggio, raccolta di dati pubblici e ricerca.
Come funziona il web scraping passo dopo passo?
A un livello di base, il funzionamento del web scraping segue una sequenza.
Uno scraper richiede una pagina, legge l’HTML o il contenuto renderizzato, identifica gli elementi target, estrae i campi necessari e li salva in un formato strutturato come JSON o CSV.
Quali sono i pro e i contro del web scraping?
I principali pro e contro del web scraping si riducono alla flessibilità rispetto all’affidabilità.
Lo scraping è flessibile perché può raccogliere dati pubblici anche quando non esiste un’API, ma è anche più fragile, più pesante in termini di manutenzione e di solito un adattamento più debole per esperienze di siti web rivolte ai clienti.
Quali sono i principali vantaggi dell’uso delle API?
I principali vantaggi dell’uso delle API sono struttura, coerenza e ripetibilità.
Le API di solito restituiscono dati più puliti, sono meno dipendenti dai cambiamenti della pagina front-end e sono più facili da connettere a flussi di lavoro a lungo termine.
Puoi usare il web scraping per i dati dei social media?
Sì, il web scraping dei dati dei social media è possibile in alcune situazioni.
Ma dalla mia esperienza, è molto meno affidabile quando l’obiettivo è pubblicare quel contenuto su un sito web in tempo reale dove la formattazione, la freschezza e la moderazione sono tutte importanti.
Perché i feed scrapati si interrompono così spesso?
I feed scrapati si interrompono spesso perché dipendono dalla struttura della pagina.
Se una piattaforma cambia il modo in cui didascalie, miniature, schede multimediali o altri elementi vengono renderizzati, lo scraper potrebbe smettere di restituire dati completi o coerenti.
Quando il web scraping ha ancora senso?
Il web scraping ha ancora senso per la ricerca, l’ascolto sociale, la raccolta di dati pubblici e alcuni esperimenti interni.
Divento molto più cauto nel raccomandarlo quando il contenuto è destinato a un’esperienza di brand rivolta ai clienti.
Qual è la differenza tra un’API diretta e una piattaforma di aggregazione?
Un’API diretta ti dà accesso grezzo ai dati di origine.
Una piattaforma di aggregazione prende questo accesso e lo trasforma in un flusso di lavoro utilizzabile aiutandoti a raccogliere, moderare, organizzare e pubblicare contenuti da più fonti.
Posso visualizzare il contenuto dei social media sul mio sito web senza scraping?
Sì.
In effetti, per la maggior parte dei brand, questo è il percorso migliore. Un flusso di lavoro di aggregazione basato su API ti consente di raccogliere prove sociali attraverso connessioni ufficiali e pubblicarle attraverso widget, caroselli, gallerie o feed di revisione senza fare affidamento su metodi di scraping fragili.
Il web scraping è più economico delle API?
Non sempre.
Lo scraping può sembrare più economico all’inizio, ma l’onere della manutenzione a lungo termine spesso cambia il quadro dei costi una volta che le correzioni, il monitoraggio, i problemi di formattazione e i guasti pubblici vengono aggiunti.
L’aggregazione di social media basata su API è migliore per i brand?
Per la maggior parte dei brand, sì.
Quando l’obiettivo è mantenere un sito web fresco con contenuti affidabili dei clienti, l’aggregazione basata su API è di solito il sistema a lungo termine migliore perché supporta la raccolta, la moderazione e la pubblicazione in un flusso di lavoro.
![11 Migliori widget di social media per siti web [+Principali casi d'uso]](https://embedsocial.com/wp-content/uploads/2023/11/embedsocial-ugc-software-landing-page-1024x688.jpg)
![Come incorporare testimonianze in un sito web nel 2026 [2 metodi + consigli]](https://embedsocial.com/wp-content/uploads/2024/09/embed-trustpilot-reviews-step-01-use-ai-to-describe-your-widget-1024x576.webp)
![Come Incorporare una Video Gallery su Siti Web [+ 5 Template Widget]](https://embedsocial.com/wp-content/uploads/2026/02/youtube-channel-section.jpg)